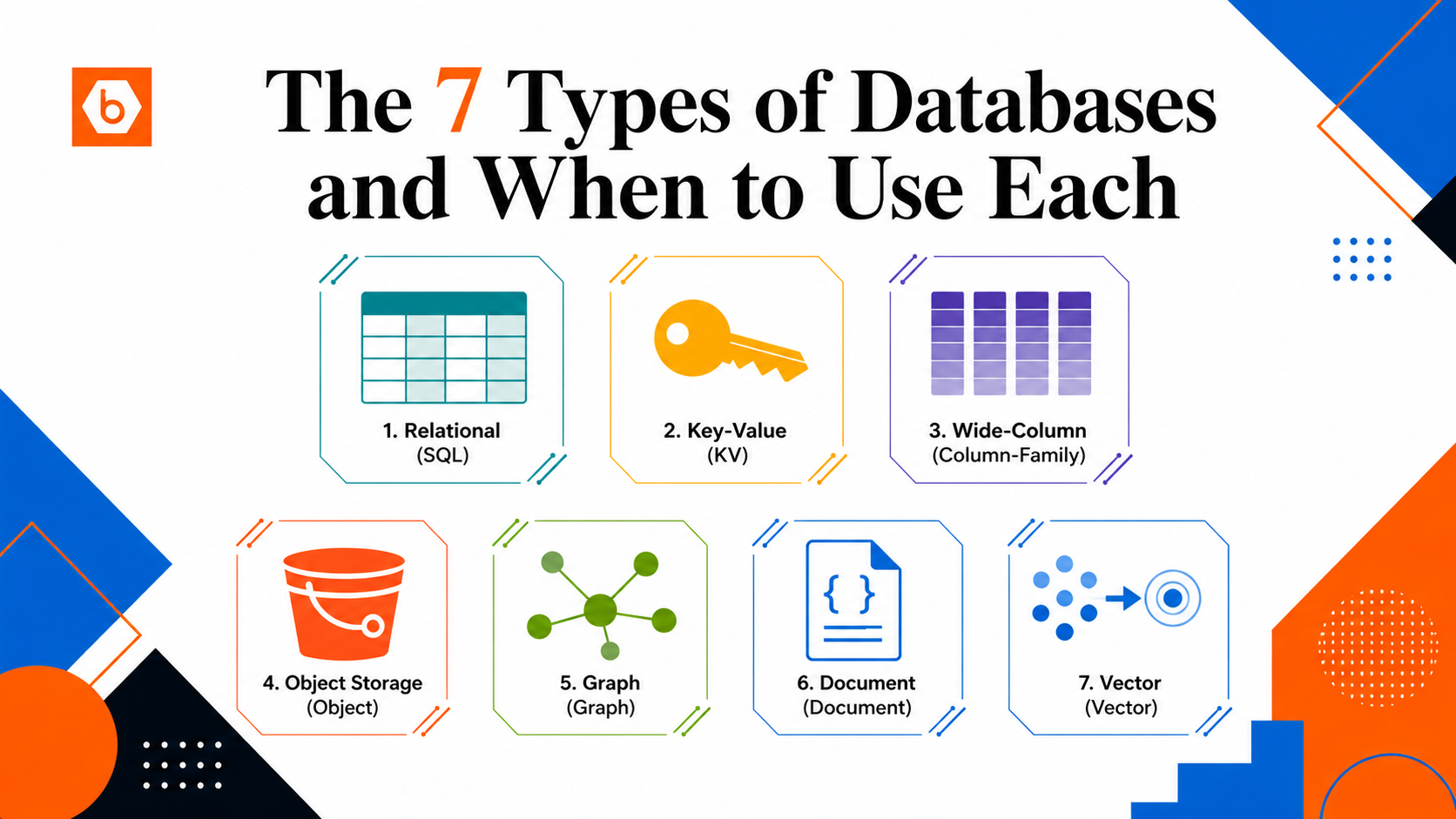

The 7 Types of Databases and When to Use Each
Here are the 7 major types of databases, how they work, and when you should actually reach for each one.
1. Relational Databases (Postgres, MySQL, SQLite)
Relational databases are essentially spreadsheets on steroids. Data lives in rows and columns, tables relate to each other via foreign keys, and you query everything with SQL.
They are fast when you query by indexed columns and slow when you do not. Under heavy load, expect to deal with connection limits and row locking on writes. But with indexing, read replicas, and caching, they scale further than people assume.
Use when: You have structured data and want query flexibility with ACID guarantees. This should be your default in most cases.
2. Key-Value Stores (Redis, DynamoDB)
A key-value store is basically a giant hash map with a database wrapper around it. Simple structure, ridiculously fast reads and writes.
The biggest downside is almost zero query flexibility. If your access pattern is not “give me the value for this exact key,” you will have a bad time. Do not try to reinvent SQL here.
Use when: You need low-latency lookups by a single key at massive scale — session storage, rate limiting, leaderboards, caching.
3. Document / NoSQL Databases (MongoDB, Firestore, CouchDB)
Document databases store data as self-contained JSON-like documents instead of rows and columns. Each document can have a completely different structure from the next, no fixed schema, no migrations required when your data shape changes.
This makes them genuinely useful early in a product's life when you are still figuring out your data model. The trade-off is real though: no joins, eventual consistency by default, and querying across documents is significantly less flexible than SQL.
The mistake teams make is reaching for MongoDB because it feels simpler upfront, then spending months working around the lack of joins and transactions as the product matures. Postgres with a JSONB column gives you most of the flexibility of a document database with none of the trade-offs.
Use when: Your data has no fixed structure, records vary significantly from each other, and you have no relational queries between different entity types. Good for catalogs, content systems, and user-generated data with unpredictable shapes.
4. Wide Column Stores (Cassandra, Bigtable)
Wide column databases are underrated. Data is stored by row keys and columns, but unlike relational databases, rows do not need to share the same columns. You can add columns dynamically.
This makes them exceptional for write-heavy workloads. The catch: you need to design carefully around your row key, because that is basically the only efficient way to access data.
Use when: You have massive write volume, predictable query patterns, and append-heavy data — think time-series metrics, IoT event logs, or activity feeds.
5. Object Storage (S3, GCS, IBEE)
“But this is not a database”, technically true, but you need to know about it and you will use it constantly. The concept is stupidly simple: put files, get files, delete files. No schema, no querying, no rows.
Object storage is the right home for any data that is a file: images, videos, backups, log archives, ML model weights, dataset snapshots. Just do not try to scan a bucket with millions of objects looking for something, always retrieve by exact key.
Use when: Your data is a blob. If “just store this thing and retrieve it by name” covers your use case, object storage is the answer and at a fraction of the cost of database storage.
6. Vector Databases (Pinecone, Weaviate, pgvector)
Vector databases store high-dimensional embeddings and let you find things that are similar to other things. They have become central to AI applications over the last two years.
The classic example: a user asks a question, that question gets embedded into a vector, the vector database returns the closest matching chunks from your knowledge base, and those chunks get passed to an LLM as context. This is retrieval-augmented generation (RAG) in a nutshell.
Use when: Your access pattern is “find similar things.” RAG pipelines, semantic search, recommendation engines, and image similarity search all live here.
7. Graph Databases (Neo4j, Neptune)
Graph databases model data as nodes and edges. They are purpose-built for relationship-heavy queries — think “friends of friends,” “what products did users who bought X also buy,” or LinkedIn’s six degrees of connection.
Traversals get expensive fast if you go too deep. Most relational databases handle simple graph-style queries just fine with a recursive CTE. Only reach for a dedicated graph database when multi-hop relationship traversal is a core, frequent operation in your product.
Use when: Your data is highly connected and multi-hop queries are the primary access pattern. Otherwise, a relational database with good indexing covers most graph-like use cases without the operational overhead.
Choosing the Right Database
Most production systems use more than one type. A typical architecture might use Postgres for transactional data, Redis for caching and session state, object storage for user-uploaded files, and a vector store for search. The question is never “which database is best” it is “which database fits this specific access pattern”.
Start with Postgres. Add other databases only when you hit a concrete limitation that another type solves better.
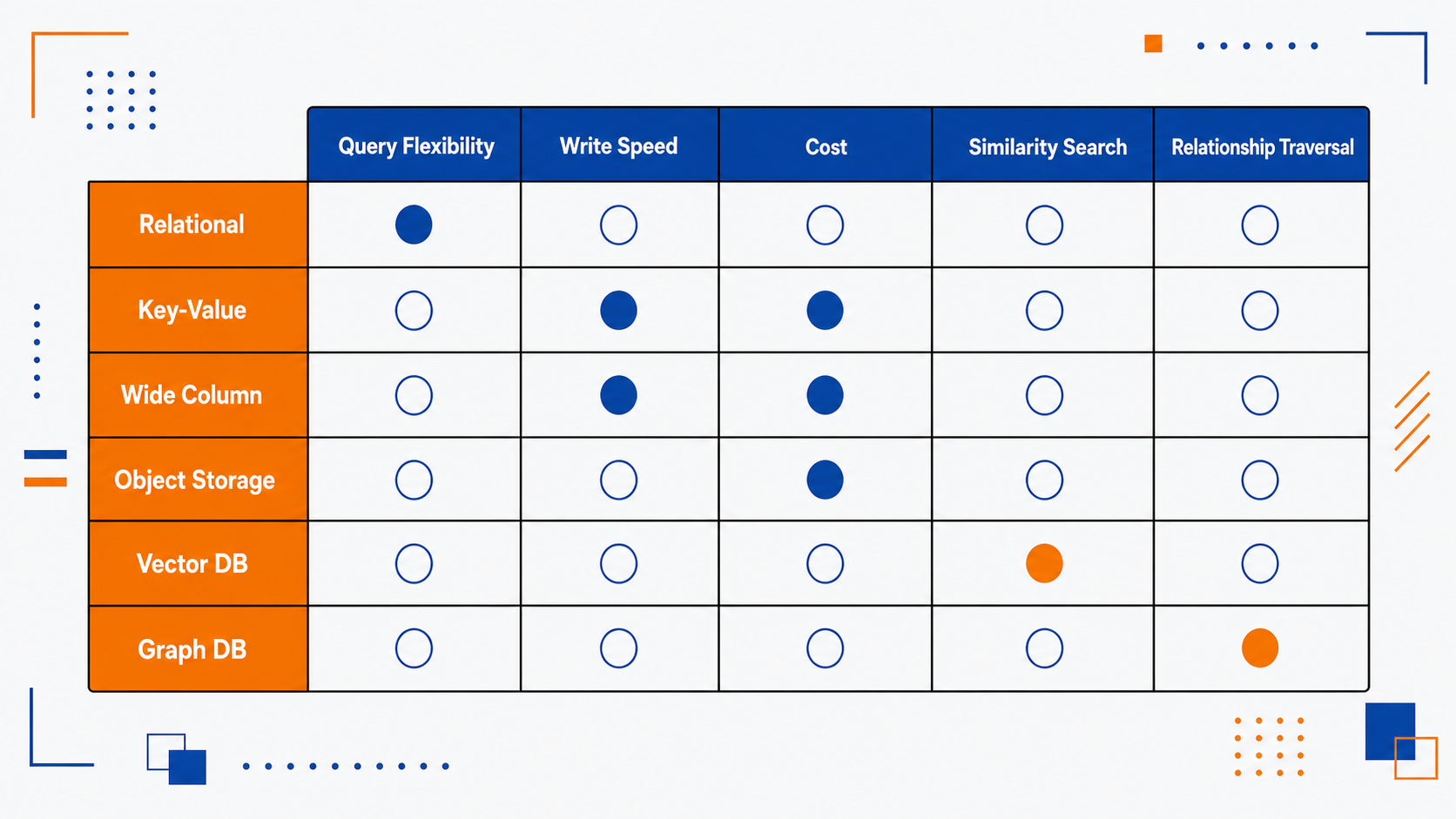
Database decision matrix
Quick Cheatsheet to Decide the Database:
Relational (Postgres, MySQL, SQLite) - Boring in the best way. Structured data, flexible queries, strong consistency. Start here and leave only when you have no other choice.
Key-Value (Redis, DynamoDB) - A giant hash map with a database wrapper. Stupid simple, stupidly fast. Caching, sessions, rate limiting. Do not try to reinvent SQL here.
Document / NoSQL (MongoDB, Firestore) - Like Postgres but without the strict schema. Great when your data shape changes a lot and data does not have relations with others. Just know what you are trading away, no joins, weaker consistency.
Wide Column (Cassandra, Bigtable) - You write a lot, you never look back. Time-series, IoT, activity feeds at scale. Operationally heavy. Most startups are not at this scale yet.
Object Storage (S3, GCS, IBEE) - Not technically a database but you will use it more than most of your databases. If your data is a file, it belongs here. Not in Postgres. Not in Redis. Here.
Vector (Pinecone, Weaviate, pgvector) - For when your access pattern is "find me things similar to this thing." RAG, semantic search, recommendations. Try pgvector inside Postgres before adding anything new.
Graph (Neo4j, Neptune) - When the relationships between your data matter as much as the data itself. Friends of friends, fraud rings, knowledge graphs. Postgres handles most graph-like queries fine until you are at real scale.