
Object Storage as the Data Lake Foundation
The data warehouse held structured data in proprietary formats, queryable only through its own engine. The data lake replaced the proprietary format with a principle: store everything in open formats on cheap, scalable object storage, and let any query engine read it.
This architecture, where object storage is the single source of truth and compute is decoupled from storage, is now the default for any serious analytics infrastructure. AWS Glue reads from S3. Databricks reads from S3. Apache Spark reads from S3. DuckDB reads from S3. The query engine is interchangeable. The storage layer is not.
IBEE's full S3 compatibility means every tool that reads data lakes from S3 reads from IBEE. For businesses that need their analytics data to remain under a specific jurisdiction, whether that is India under DPDP and RBI requirements, the EU under GDPR, or any other sovereign framework, this is the path to a data lake that satisfies both the engineering team and the legal team. The architecture is identical to an AWS S3-based data lake. The jurisdiction is different.
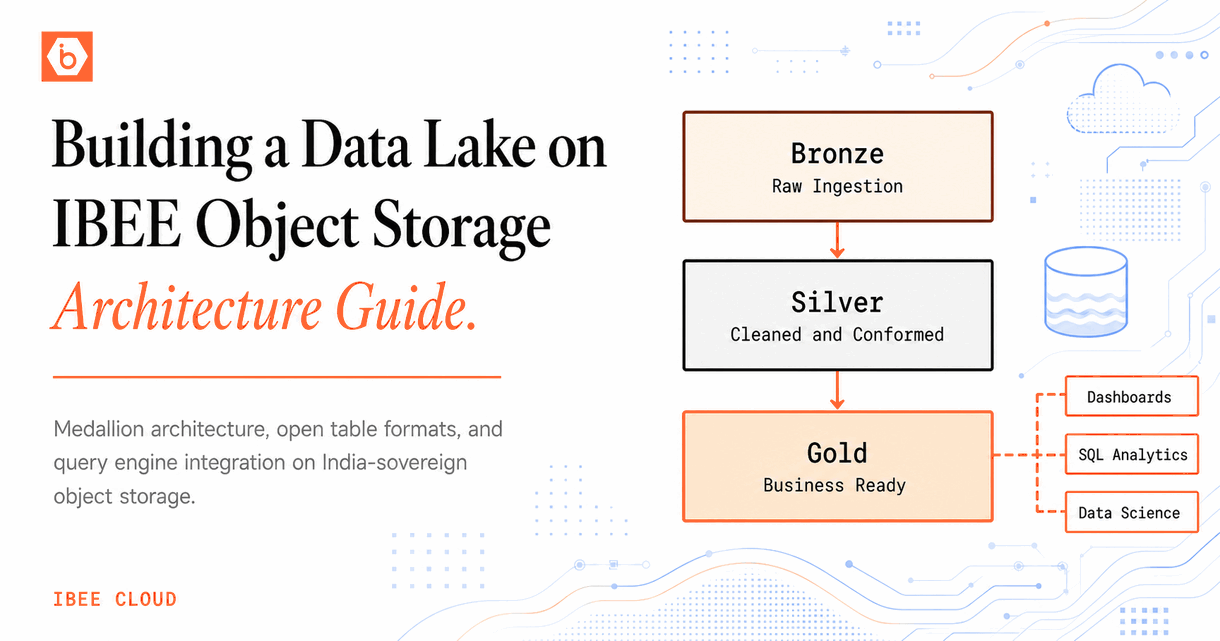
The Medallion Architecture
The most widely adopted data lake structure is the medallion architecture: three layers of data refinement, each stored in the same object storage system, each serving a different consumer. The diagram below shows how data flows through the three layers and which consumers read from each.
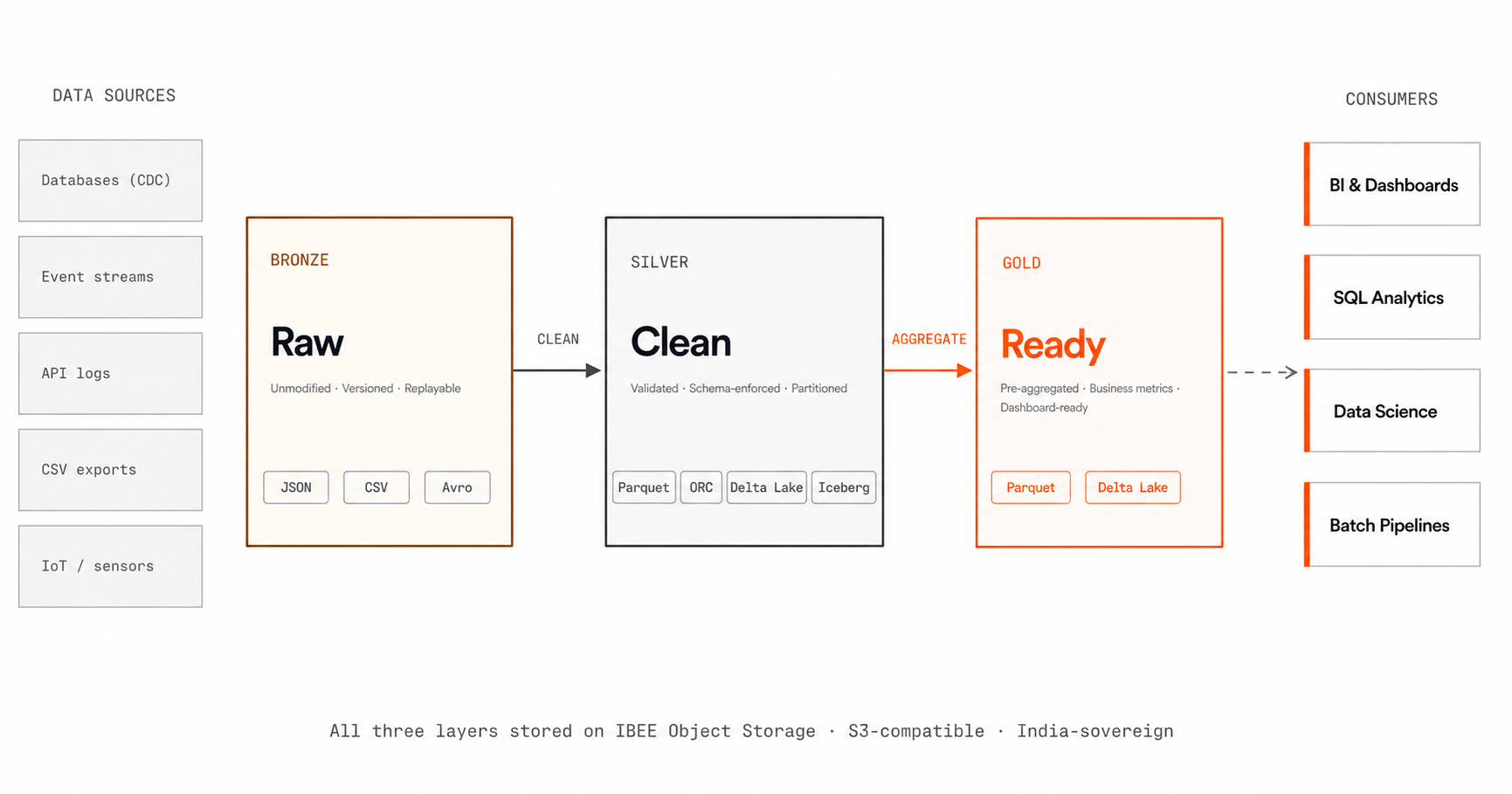
Bronze holds raw data as ingested. Silver holds cleaned, schema-enforced data. Gold holds pre-aggregated business metrics ready for dashboards and reporting.
Bronze: Raw Ingestion Layer
The bronze layer stores data exactly as it arrives from source systems, unmodified, unvalidated, in whatever format the source emitted. Database change data capture streams, API event logs, CSV exports from business systems, IoT sensor readings, clickstream data: all of it lands in the bronze bucket exactly as received.
The purpose of the bronze layer is durability and reproducibility. If a transformation in the silver layer turns out to be wrong, you can replay from bronze. If a source system changes its schema, the bronze record of what the data looked like before the change is preserved. We have seen teams avoid weeks of data recovery work by having a clean bronze layer to replay from when a silver transformation bug propagated silently for several days before being caught.
On IBEE, the bronze bucket is configured with versioning enabled, so objects written by streaming ingestion pipelines are preserved even if keys are reused. Write-once, never-delete is the operating principle for bronze.
Silver: Cleaned and Conformed Layer
The silver layer contains data that has been validated, deduplicated, schema-enforced, and conformed to a standard format. Bronze JSON events become silver Parquet files with consistent column types and null handling. Bronze CSV exports become silver tables with normalised date formats and trimmed string values.
Silver data is queryable by analysts who need reliable, clean data but do not need it to be pre-aggregated. A data scientist building a churn model reads from silver. A fraud detection pipeline training on transaction history reads from silver.
Silver data is typically stored in Parquet or ORC format, partitioned by date or entity key. This partitioning structure is what allows query engines to push down partition filters and avoid reading the entire dataset for time-bounded queries.
Gold: Business-Ready Aggregated Layer
The gold layer contains pre-aggregated, business-metric-aligned data: daily user activity summaries, weekly revenue by geography, monthly cohort retention tables. Gold data feeds dashboards, business intelligence tools, and executive reporting.
Gold tables are typically small compared to silver because aggregation compresses many raw events into a single summary row. They are optimised for fast read performance and are partitioned to match the time granularity of the reports they serve.
Open Table Formats: Delta Lake and Apache Iceberg
Raw Parquet files in a data lake work for simple analytics. At production scale, two problems emerge: concurrent writes from multiple pipelines corrupt the directory structure, and schema evolution over time makes it impossible to know what columns a given file contains without reading it.
Open table formats solve both problems by adding a transaction log on top of the raw Parquet files. Delta Lake and Apache Iceberg are the two dominant options, and both work on IBEE's S3-compatible storage (Rs.1.50/GB/month, $0.016/GB/month) with no modification.
Delta Lake stores a _delta_log directory alongside the data files in each table's S3 prefix. Every write to the table, whether an append, overwrite, merge, or delete, creates a new entry in the transaction log. Readers use the log to determine which files are part of the current table snapshot. Delta Lake provides ACID transactions, schema enforcement, time travel (the ability to query the table as it was at any previous point), and schema evolution.
Apache Iceberg achieves the same goals with a different metadata model: a tree of metadata files that track current and historical snapshots of the table. Iceberg has stronger support for partition evolution, meaning you can change how the table is partitioned without rewriting all the data, and for hidden partitioning, meaning the table tracks partition values without requiring them to appear as directory names in the path.
Both formats read and write data from S3-compatible storage. Both work on IBEE by pointing the Spark configuration or the Iceberg catalog at IBEE's endpoint.
Query Engine Integration
The value of the data lake architecture is that the storage layer is decoupled from the query layer. Multiple engines can read the same data simultaneously. The table below shows the main query engines, their primary use case, and the configuration change required to point them at IBEE instead of AWS S3.

Every engine requires the same two configuration changes: set the S3 endpoint to IBEE and enable path-style access.
Ingestion Patterns for the IBEE Data Lake
Batch ingestion from relational databases uses tools such as Airbyte, dbt, or custom Spark jobs. The typical pattern is extract from source, transform into target schema, and write Parquet to the silver bucket on a schedule.
Stream ingestion from event queues such as Kafka or Pulsar uses Flink or Spark Streaming to consume events and write micro-batch Parquet files to the bronze bucket in near real-time. S3-compatible storage is the standard checkpoint and output store for both engines.
Change data capture from databases uses Debezium to stream row-level changes to Kafka, then Flink to write change events to the bronze bucket. This captures every insert, update, and delete from the source database without impacting source query performance.
Data Governance on Sovereign Storage
For enterprises running data lakes with customer data, financial records, or regulated data, the jurisdiction of the storage layer carries the same compliance weight as the technical capabilities. A data lake on AWS S3 or GCP Cloud Storage contains enterprise data on infrastructure governed by US federal law, regardless of the physical region. A data lake on IBEE contains the same data on India-sovereign infrastructure, governed by Indian law.
For businesses subject to DPDP Act obligations, RBI data localisation requirements, or enterprise contracts that require India-resident data custody, IBEE provides the sovereignty guarantee that hyperscaler storage cannot. The same argument applies globally: EU businesses under GDPR, healthcare organisations under HIPAA, and financial services firms under FCA or SEC frameworks all face equivalent pressure to establish clear data jurisdiction at the storage layer.
Getting Started
Create your bronze, silver, and gold buckets on IBEE. Configure your Spark or Flink cluster with IBEE's S3 endpoint and path-style access enabled. Start with batch ingestion from your primary data source into the bronze bucket. Add a silver transformation job. Query with DuckDB or Trino. The full configuration reference for each engine is at ibee.ai/docs.





