The Storage Layers Most Teams Underplan
A RAG system feels architecturally simple: documents go in, embeddings get generated, queries retrieve relevant chunks, the LLM generates a response. The storage complexity is hidden in the details.
In practice, a production RAG system has at least five distinct storage concerns: the raw source documents, the processed and chunked text, the embedding vectors and their metadata, the conversation and session history, and the fine-tuned model weights if the team is running its own models. Each of these has different access patterns, different retention requirements, and different storage technology choices.
Teams that treat all of this as a single data problem end up with architectures where a document update requires re-indexing the entire corpus, where conversation history cannot be audited, or where model rollbacks require reprocessing weeks of training data. We have seen this pattern at Indian AI startups that moved fast at the prototype stage and discovered the storage debt only when a production incident required tracing which document version contributed to a specific LLM response.
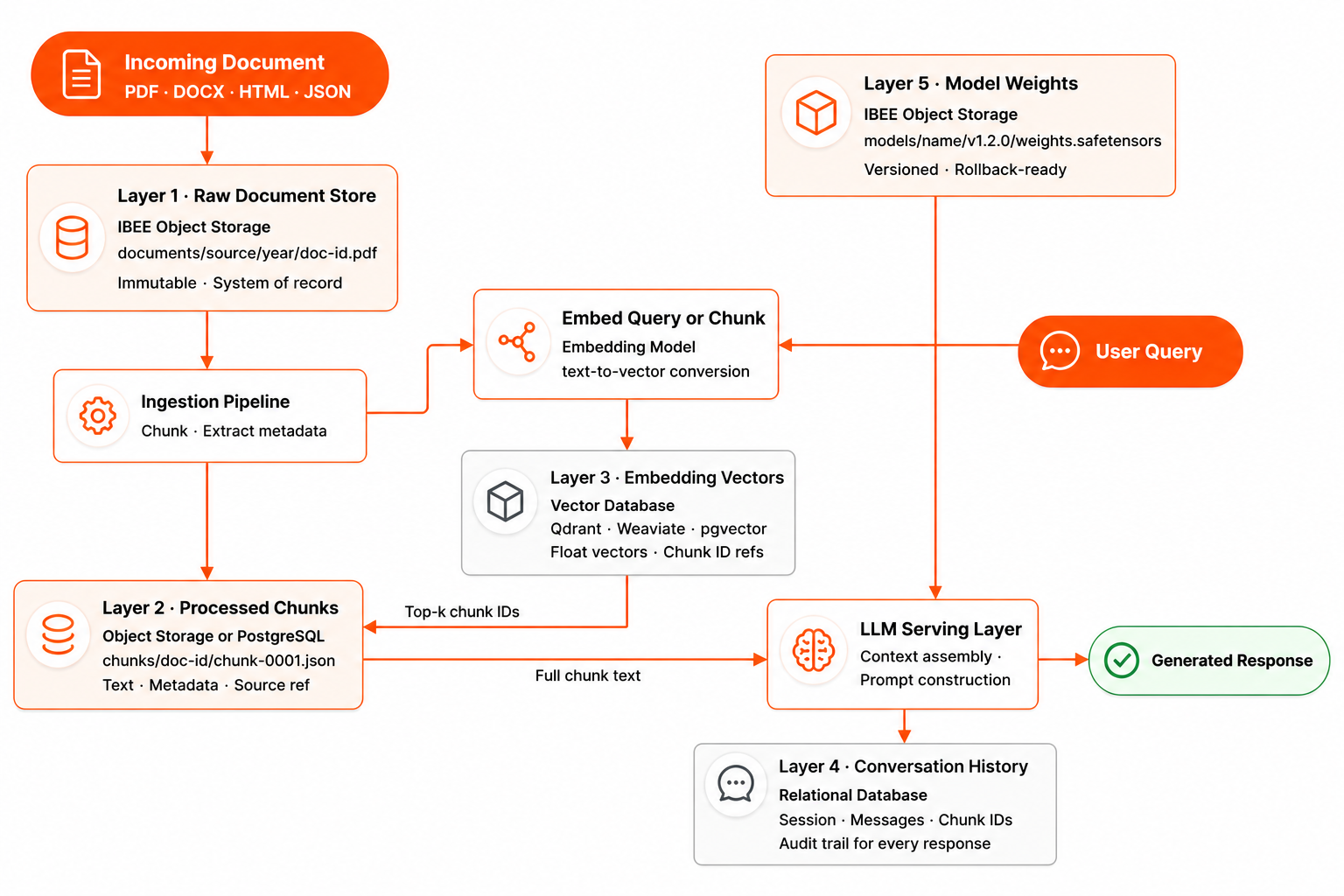
Each layer has a different access pattern, retention requirement, and storage technology.
Layer 1: Raw Document Storage
The raw document layer is the system of record. Every document ingested into the RAG system, whether PDFs, Word files, web pages, Markdown files, or structured data exports, is stored here in its original form, unchanged.
Object storage is the right home for raw documents. Documents are typically large relative to text, rarely accessed after initial processing, and need to be preserved indefinitely in case re-processing is needed with a new chunking strategy or embedding model.
Store documents in IBEE with a stable, deterministic key derived from the document's source identity: documents/source/year/month/document-id.pdf. The key structure enables listing by source, by date range, or by document ID without full corpus scans.
Keep raw documents immutable. If a document is updated at the source, add a new version with a new document ID and timestamp rather than overwriting the previous version. The change history is part of the audit trail, and for regulated applications it is often a compliance requirement.
The practical advantage of preserving raw documents in object storage becomes clear when the embedding model changes. When switching from one embedding model to another, all chunk embeddings need to be regenerated. With raw documents preserved in IBEE, re-processing is a compute cost. Without them, it is a data recovery problem.
Layer 2: Processed Chunks
After ingestion, documents are split into chunks of a configured size and overlap, typically 512 to 2000 tokens with 10 to 20 percent overlap. Each chunk is stored with its source document reference, position within the document, and any extracted metadata such as section heading, page number, and document date.
Processed chunks belong in a lightweight, queryable store: either object storage as JSON files with the chunk text and metadata, or a PostgreSQL table with a JSON column for metadata.
Object storage is appropriate for large corpora of millions of chunks where the chunk store is rebuilt from raw documents when re-indexing. A relational database is appropriate for smaller corpora where incremental updates, adding a new document's chunks without touching existing ones, are important for operational efficiency.
For object storage, store chunks under chunks/document-id/chunk-{n:04d}.json. This key structure allows all chunks from a specific document to be deleted by prefix, without scanning unrelated chunks, which is useful for document removal workflows in systems with deletion obligations.
Layer 3: Embedding Vectors
Embedding vectors are the numerically dense representations of text chunks that enable semantic search. They are generated by an embedding model and stored in a vector database that supports approximate nearest-neighbour search.
The vector database is a specialist store, not object storage and not a relational database. Options available for Indian teams include Qdrant (open-source, self-hosted), Weaviate (open-source, self-hosted or cloud), pgvector (PostgreSQL extension), and Chroma (lightweight, suitable for development and small-scale production).
The vector database stores embedding vectors alongside the chunk metadata needed to retrieve the source text: the document ID, chunk index, and a truncated preview of the chunk text. It does not store the full chunk text. That lives in the chunk store at layer 2 and is retrieved by ID after the vector search identifies relevant chunks.
Keeping layers two and three in sync is the most operationally demanding part of a production RAG system. When a document is updated or deleted, the corresponding chunks in layer 2 and their embedding vectors in layer 3 must both be updated. The solution is to maintain a mapping from document ID to chunk IDs to vector IDs in a relational database. This mapping is what enables clean document-level updates and deletions without triggering a full re-index of the corpus.
Layer 4: Conversation and Session History
Conversation history, the multi-turn context that allows an LLM to refer to earlier parts of a conversation, needs low-latency reads and writes and structured querying. Object storage is not appropriate here. A relational database with indexed columns is.
Store conversations with the following structure: session ID, user ID, message sequence number, role (user or assistant), message content, timestamp, and the retrieved chunk IDs that were used to generate the assistant's response.
The retrieved chunk IDs are the audit trail for each LLM response. They allow tracing which documents contributed to a given answer, which is increasingly important for regulated applications in financial advice, medical information, and legal guidance where the provenance of AI-generated responses must be explainable to a regulator or a client.
Layer 5: Fine-Tuned Model Weights
If the product involves fine-tuning a base LLM on domain-specific data, whether legal documents, medical literature, financial reports, or Indian language corpora, the resulting model weights need to be stored, versioned, and deployable.
Object storage is the correct store for model weights. A fine-tuned 7B parameter model produces weights of approximately 14 to 28 GB depending on quantisation. Store weights in IBEE under models/model-name/v1.2.0/weights.safetensors. Versioned key prefixes allow rolling back to a previous model version by pointing the serving layer at the previous prefix without any data movement.
Store the training configuration and a record of the training dataset version alongside the weights. The ability to reproduce a given model version is as important as the ability to serve it, and the two are connected by the run ID that links the weights, the dataset version, and the training parameters.
The India-Sovereignty Dimension
For Indian AI companies building on documents that contain Indian user data, including medical records, legal filings, financial documents, and government records, the data residency of the RAG system's document store is a compliance question, not just an architectural preference.
A RAG system ingesting Indian health records where the raw document store lives on AWS S3 or GCP means Indian health data is processed on infrastructure subject to US federal law. For healthcare AI companies with hospital clients, this is a procurement barrier that surfaces during vendor due diligence. For companies building on government document corpora, it may be a direct legal requirement under the National Data Governance Framework.
IBEE's India-sovereign storage provides the document store layer on Indian infrastructure, under Indian law. The vector database and relational database layers can run on self-hosted compute within the same Indian data centre.
The complete RAG system can be India-resident end to end, which means the compliance answer to data residency questions is architectural rather than contractual.
For teams building production RAG systems, IBEE is also working on a managed vector and RAG infrastructure layer on Indian sovereign infrastructure, purpose-built for the architecture described in this article, so the full five-layer stack can run on a single India-resident platform without assembling each component separately. If you are building in this space and want early access, reach out to the IBEE team directly.