The Data Infrastructure Problem Most AI Teams Face
ML teams building serious products encounter the same infrastructure challenge at different scales: training data lives in one place, GPU compute lives in another, and the cost of moving data between them, whether in money or in latency, is the hidden tax on every training run.
For a team training on a few gigabytes, this is a minor inconvenience. For a team training on hundreds of gigabytes of domain-specific data, whether that is Indian language corpora, European healthcare records, financial documents, or user-generated content with data residency obligations, the architecture of the storage layer is not a secondary concern. It determines training throughput, compliance posture, and the cost model for data access as the dataset scales.
We have seen teams lose weeks of engineering time untangling a storage architecture that was never designed for the scale it eventually reached. The pipeline described here is built to hold up from the first training run to the thousandth.
This guide describes the architecture that solves this problem: object storage as the persistent data layer, GPU compute as a stateless processing layer that reads from and writes to storage, and a pipeline structure that makes data access efficient at scale.
The Architecture: Storage-Centric AI Infrastructure
The core principle is that the data is permanent and the compute is ephemeral. Training jobs start, consume data from object storage, produce model artefacts that are written back to object storage, and terminate. The storage persists between runs. The GPU instance does not need to.
This architecture delivers three concrete advantages. Training jobs can be restarted from any checkpoint without data loss. Multiple training jobs can access the same dataset simultaneously without copying data. And the cost of GPU compute is paid only for the duration of active training, not for idle time while data is being staged or managed.
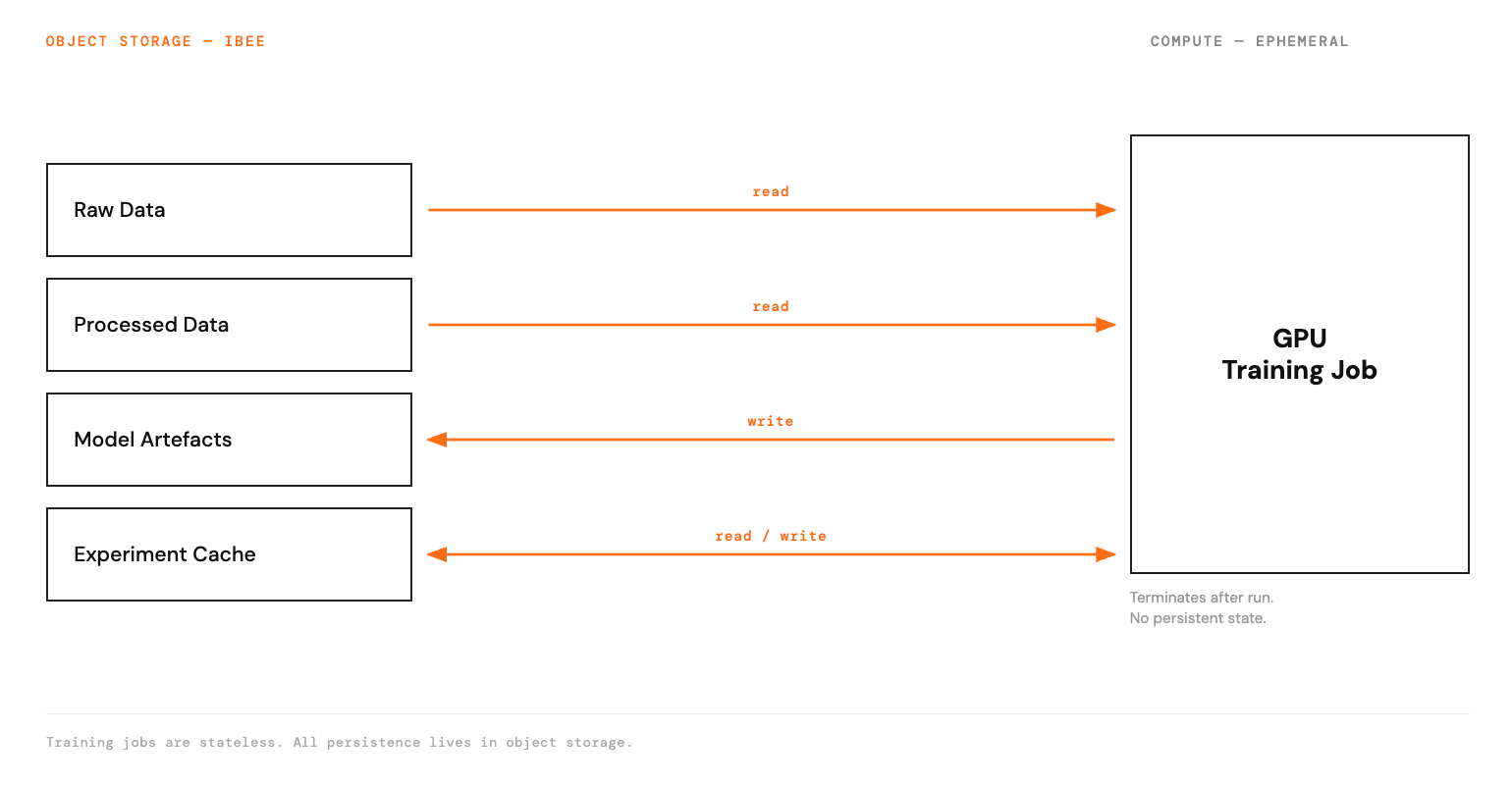
Raw data and model artefacts persist in object storage. GPU compute is stateless.
Storage Layer
The storage layer holds everything that needs to persist between training runs, organised across four buckets.
The raw data bucket holds source datasets as collected, never modified. Every file has a stable key that uniquely identifies it across all training runs. The contents vary by domain: language corpora, user interaction logs, labelled medical images, financial transaction records. Whatever the domain, raw data is immutable in this bucket.
The processed data bucket holds training-ready datasets produced from raw data by preprocessing pipelines. These are stored as WebDataset shards, Parquet files, or TFRecord files depending on the training framework, and versioned by dataset version number in the key prefix.
The model artefacts bucket holds checkpoints written during training, final model weights, and evaluation outputs. Each training run writes to a prefix identified by a unique run ID, so artefacts from every run are preserved and addressable.
The experiment cache bucket holds preprocessed features, tokenised text, and cached embeddings: intermediate representations that are expensive to compute and reused across multiple training experiments.
Compute Layer
Training jobs are Python processes running on GPU instances. They connect to object storage at startup, stream training data through the dataloader, write checkpoints at configured intervals, and write final artefacts at completion.
The GPU instance has no persistent storage obligation. It is a processing node that reads from and writes to the storage layer. When training completes, the instance can be terminated without data loss, because everything produced is already in object storage.
Data Loading: The Training Throughput Bottleneck
The most common performance problem in this architecture is data loading throughput. A GPU that can process data faster than the dataloader can feed it is GPU time wasted. On object storage, data loading throughput depends on three variables: the number of objects and the per-request overhead of individual GET calls, the size of each object, and the parallelism of the dataloader.
Sharding is the most effective single optimisation. Instead of storing one million individual training examples as individual files, which means one million GET requests per epoch, package them into shards of 500 to 1000 examples each using the WebDataset format. One thousand shards of 1000 examples each means 1000 GET requests per epoch rather than one million. Each GET retrieves a tar archive of examples that the dataloader processes locally.
In practice, switching from per-file storage to sharded WebDataset format is the single change that most consistently unblocks training throughput for teams we work with — the improvement in data loading speed often makes the GPU the bottleneck for the first time.
Parallel prefetching compounds this. Both PyTorch DataLoader and TensorFlow's tf.data pipeline support parallel prefetching: loading the next batch of shards while the GPU processes the current batch. Setting numworkers in PyTorch or numparallel_calls in TensorFlow to match available CPU cores on the training instance keeps the GPU fully fed.
For training runs spanning multiple epochs, caching to local NVMe on the first epoch pass removes the dependency on storage network bandwidth entirely. Download all shards to local disk on the first pass and serve subsequent epochs from local storage. After the first epoch, data loading throughput is bounded only by local disk speed, not by the object storage connection.
Connecting Training Jobs to IBEE
Training frameworks that use the AWS S3 client connect to IBEE by setting the endpoint URL environment variable to IBEE's S3-compatible endpoint, alongside the access key and secret key for the IBEE bucket. With AWSENDPOINTURL set, the AWS SDK automatically routes all S3 calls to IBEE. This applies to boto3, the AWS CLI, and any library that uses the AWS SDK, including PyTorch's S3 DataLoader integration and Hugging Face Datasets, without any code changes to the training logic itself.
For PyTorch with WebDataset, the pipeline initialises by listing the processed data bucket to retrieve all shard URLs, constructs a WebDataset pipeline over those URLs, and wraps it in a DataLoader with the desired number of workers and prefetch buffer size. The dataset reads directly from IBEE object storage as training progresses.
Because IBEE is fully S3-compatible, the same pipeline configuration runs against AWS S3 by changing a single environment variable. There is no rewrite required when moving between environments.
Checkpoint Strategy for Long Training Runs
Training runs that take 12 to 48 hours without a checkpoint strategy lose all progress if the instance is interrupted. The correct approach is to write checkpoints to object storage at regular intervals: every 1000 steps or every hour, whichever is more frequent.
At training startup, the job lists the checkpoints prefix for its run ID, identifies the checkpoint with the highest step number, and resumes from that point. If no checkpoint exists, training begins from scratch. This pattern makes training jobs fully resumable at any scale, with no dependency on instance-level state.
Data Residency and Sovereign AI Infrastructure
For AI companies building models on regulated or sensitive data, the data residency of the training infrastructure carries the same compliance weight as the residency of the production serving infrastructure. This is a pattern we see consistently across geographies, not just India.
In the European Union, GDPR and national data protection frameworks create pressure for training data and model artefacts to remain within EU jurisdiction, particularly for healthcare, financial services, and public sector AI applications. In the United States, HIPAA-covered entities building clinical AI models face similar requirements around where patient data can be processed. In India, DPDP obligations and CERT-In guidelines apply to companies processing Indian user data, with specific requirements for data localisation in regulated sectors. Government and enterprise procurement processes in each of these markets increasingly ask where training data resided, and what legal jurisdiction governed it, as part of AI vendor due diligence. We have spoken with AI founders who cleared every other enterprise procurement checkpoint only to stall on this question — and had to retrofit a compliant storage architecture under deadline pressure.
Training a model on data stored in a foreign-jurisdiction cloud means the raw data, intermediate representations, and model artefacts derived from that data all resided under foreign law during the training process. The compliance question extends to the artefacts, not just the raw data.
IBEE's India-sovereign storage provides a clean answer for Indian AI companies and for global AI companies with Indian data: raw data, processed training datasets, and model artefacts all reside on Indian infrastructure under Indian law, with no US CLOUD Act exposure, 180-day audit log retention, and AES-256 encryption with TLS 1.3 in transit, both on by default. For AI companies with enterprise customers, government clients, or products in regulated sectors, this is an architecture decision with compliance implications beyond the technical.