The Two Multi-Tenant Storage Models
Every B2B SaaS product that stores files must choose between two object storage architectures. Each has a distinct tradeoff profile, and the right choice is determined less by technical preference and more by the regulatory exposure of your customer base.
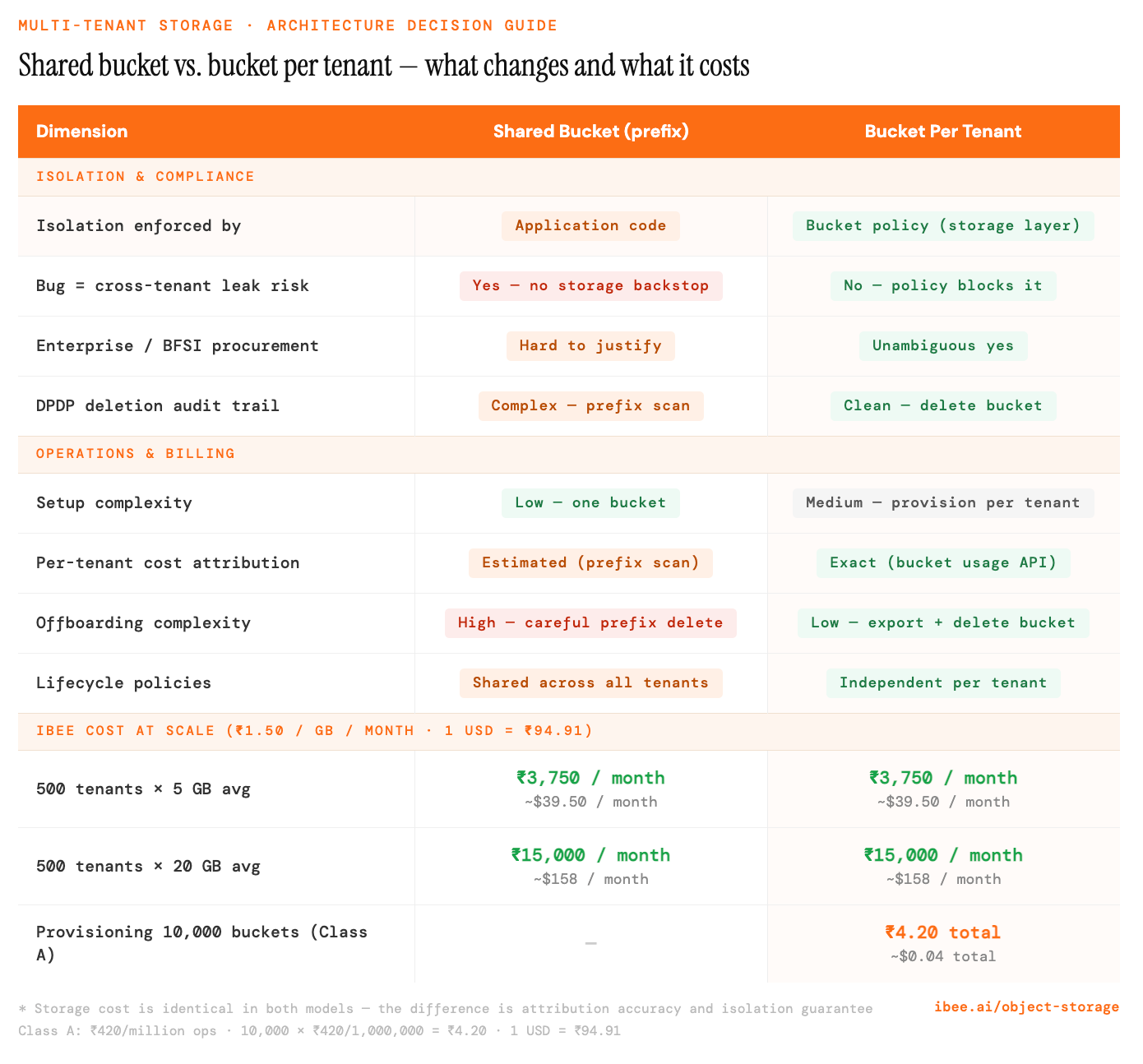
The first model is shared bucket with prefix isolation. All tenant data lives in one bucket, separated by a key prefix: tenant-abc123/documents/file.pdf. The application enforces isolation through access control: every query that reads or writes objects includes the tenant ID in the key, and the application layer validates that the requesting user's tenant ID matches the key prefix they are accessing.
The second model is bucket per tenant. Each tenant has a dedicated bucket: mycompany-tenant-abc123. The bucket boundary enforces isolation at the storage layer. A misconfiguration in the application access control layer cannot expose one tenant's data to another, because the bucket policy prevents it by design.
Neither model is universally correct. The choice depends on your tenant count, data volume per tenant, compliance requirements, and what your enterprise clients expect when the data isolation question surfaces in procurement.
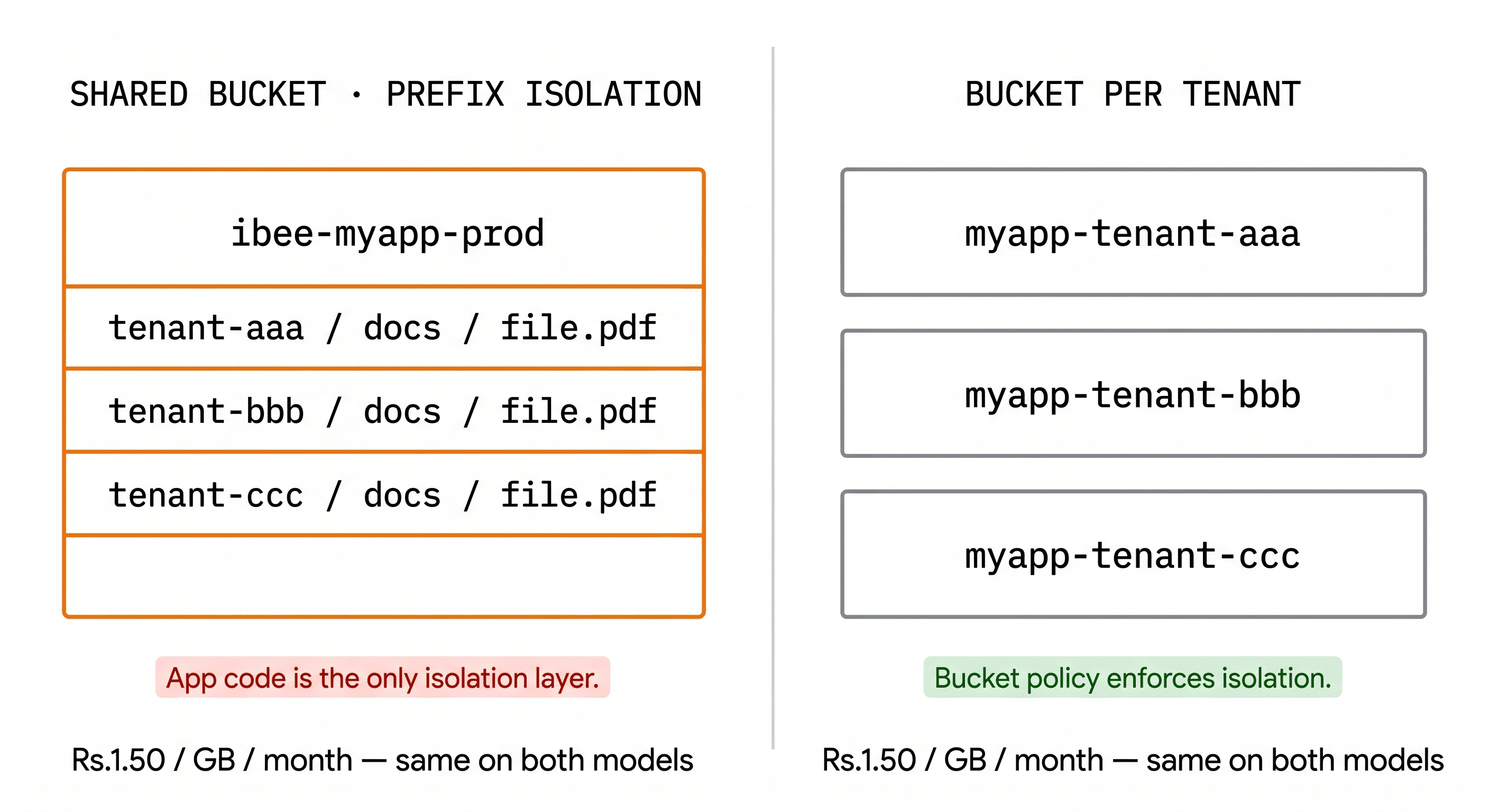
Shared prefix scales simply. Bucket-per-tenant scales safely.
Shared Bucket: When It Is Appropriate
A shared bucket with prefix isolation works well at the early-growth stage: hundreds of tenants rather than tens of thousands, modest data volumes per tenant averaging under 10 GB, a primarily SMB customer base with no explicit data isolation contracts, and an engineering team with the capacity to enforce tenant scoping consistently across every code path.
We have reviewed storage architecture for enough Indian SaaS products to know that most teams start with shared prefix isolation and switch to bucket-per-tenant the first time an enterprise client's procurement team asks the isolation question in a contract review. Starting with shared prefix is not wrong. It is the correct choice for the stage, and the migration path to bucket-per-tenant, while not trivial, is well-understood.
For a product at this stage, shared prefix isolation is simpler in every operational dimension: one bucket to provision, one set of credentials to manage, straightforward Terraform or IaC configuration, and no per-tenant provisioning logic to maintain. At IBEE's storage rate of Rs.1.50 per GB per month with ingress free, a shared bucket holding 1 TB across 500 tenants costs Rs.1,500 per month with no provisioning overhead beyond the initial bucket setup.
The discipline this model requires is consistent: every code path that generates presigned URLs, reads objects, or writes objects must include the tenant ID in the key. The most reliable enforcement mechanism is a storage service class that always prepends the tenant ID before executing any S3 operation. Code review should flag any S3 call that constructs a key without first passing through that class. This is an architectural pattern, not a policy — it needs to be built into the codebase from the start, not enforced retroactively.
The structural limitation is equally consistent: a bug in the tenant scoping logic has no safety net at the storage layer. If the application accidentally constructs a key with the wrong tenant ID, the storage layer will serve the object without complaint. For customers in regulated sectors such as BFSI, healthcare, legal, or government, this risk is not acceptable regardless of how disciplined the application code is.
Bucket Per Tenant: When It Is Required
Bucket per tenant becomes the correct architecture when any one of the following conditions is true: an enterprise or regulated-sector client asks about data isolation guarantees during procurement, the product handles data in BFSI, healthcare, legal, or government contexts where co-tenancy is a concern, individual tenant data volumes are large enough to warrant independent lifecycle policies, or the team needs clean and auditable data deletion to satisfy DPDP Act obligations.
With bucket per tenant, the bucket policy enforces isolation at the storage layer regardless of what happens in application code. Even if a logic error causes the application to request an object from another tenant's bucket, the bucket policy denies the request. The storage layer itself is the backstop, not the application.
Enterprise procurement teams at banks, hospitals, and large corporates will ask: "Is our data stored separately from other customers?" With bucket per tenant, the answer is unambiguous and documentable: yes, in a dedicated bucket with its own access policy. With shared prefix isolation, the answer is accurate but harder to sell: yes, separated by a key prefix in a shared bucket. Some procurement teams will not accept the second answer regardless of how it is explained, particularly in BFSI where data residency and co-tenancy restrictions may appear in the regulatory guidance itself.
In our experience, the data isolation question surfaces at a predictable point in the sales process: when the first bank, hospital, or large corporate enters procurement. Re-architecting from shared prefix to bucket-per-tenant mid-contract, while managing existing tenants and maintaining uptime, is significantly more painful than having built it correctly from the start. The operational cost of the migration is almost always higher than the operational cost of bucket-per-tenant from day one.
Implementing Bucket Per Tenant on IBEE
Because IBEE is fully S3-compatible, bucket provisioning on tenant signup uses standard AWS SDK calls with the IBEE endpoint substituted. No SDK changes or new libraries are required. The provisioning logic belongs in the tenant onboarding service: when a new tenant organisation is created in the system, the service creates a dedicated bucket, applies the tenant-scoped access policy, and stores the bucket name against the tenant record in the application database.
The important implementation detail is to store the tenant-to-bucket mapping in the database and retrieve it at runtime, rather than constructing the bucket name dynamically from the tenant ID at the point of each S3 operation. This decoupling means the bucket can be renamed or migrated to a different endpoint without a code change. The database becomes the single source of truth for all tenant storage routing, and the provisioning step is the only place that creates the mapping.
With IBEE at Rs.1.50 per GB per month and ingress free, provisioning a new tenant bucket costs nothing until the tenant starts writing data. There is no minimum bucket size, no per-bucket subscription charge, and no API cost for the provisioning operation itself beyond the standard Class A operation rate of Rs.420 per million requests ($4.43/million). At that rate, provisioning 10,000 tenant buckets costs Rs.4.20 in API fees.
Per-Tenant Storage Billing
Exact, auditable per-tenant billing and no prefix estimation needed.
Tenant Offboarding and Data Export
Offboarding a tenant with bucket per tenant is a clean and auditable process. When a contract ends, the offboarding workflow exports all objects from the tenant's bucket to a compressed archive using a tool like rclone, makes that archive available to the tenant for download, and records the export timestamp in the audit log. This satisfies the data portability obligation under the contract and under the DPDP Act's right-to-data-portability provisions.
The bucket is then retained for the contractual data retention period, typically 30 to 90 days after the contract end date. At the end of the retention period, the bucket and all its objects are deleted, and the deletion timestamp is recorded in the audit log alongside the tenant ID, bucket name, and the identity of the operator who executed the deletion. The entire offboarding sequence should be scripted and idempotent: it can be interrupted and re-run without risk of partial deletion or data loss.
DPDP Act compliance has made this question more concrete for Indian SaaS teams in particular. Enterprise clients are beginning to ask not just where their data lives, but how it gets deleted when the contract ends, and they are asking for evidence rather than assurances. Bucket-per-tenant gives a clean, auditable answer to both questions, and that answer can be written into the Data Processing Agreement without qualification.
With shared prefix isolation, the equivalent offboarding process requires carefully deleting all objects under the tenant's key prefix, a more complex operation with a higher risk of accidentally affecting neighbouring prefixes, and a harder answer to give a compliance team that is asking for documented evidence of clean data deletion.