Most teams don’t “design” logging. They accumulate it.
You ship a service, you turn on logs, and within a month your hot search cluster is on fire. Engineers start asking for “just the last 24 hours” and nobody knows where logs went after that. Then security shows up and asks why audit logs are editable, or why the retention policy is “whatever the index still has left.”
Here’s the uncomfortable truth: most teams choose their logging storage first, then try to force their access patterns to fit. That’s backwards. You need a storage architecture that matches how people actually use logs: fast for recent debugging, cheap for long retention, and locked down for audit.
The failure mode you should design out
The most common pattern looks like this. Your ingestion pipeline writes everything into the same system, usually something search-indexed. It’s convenient because queries are fast on day one. Then usage grows.
Costs climb in three places at once: indexing overhead, storage footprint, and operational drag (shards, compaction, reindexing, retention rollovers). Meanwhile, your users do not query logs uniformly. They query the recent window constantly and the older windows rarely, until an incident forces an investigation.
Most teams get this wrong in a very specific way: they set a “7 days hot retention” because someone said that’s standard, not because they measured. If your mean time to incident is 30 days, you just made cold storage mandatory during the most important moments. If your audit retention is 7 years, you just guaranteed you will either (a) blow up your hot tier costs or (b) violate the audit requirement with a “best effort” setup.
You don’t need more logging. You need tiering with rules you can prove.
Required architecture diagram: tiered logging with lifecycle routing
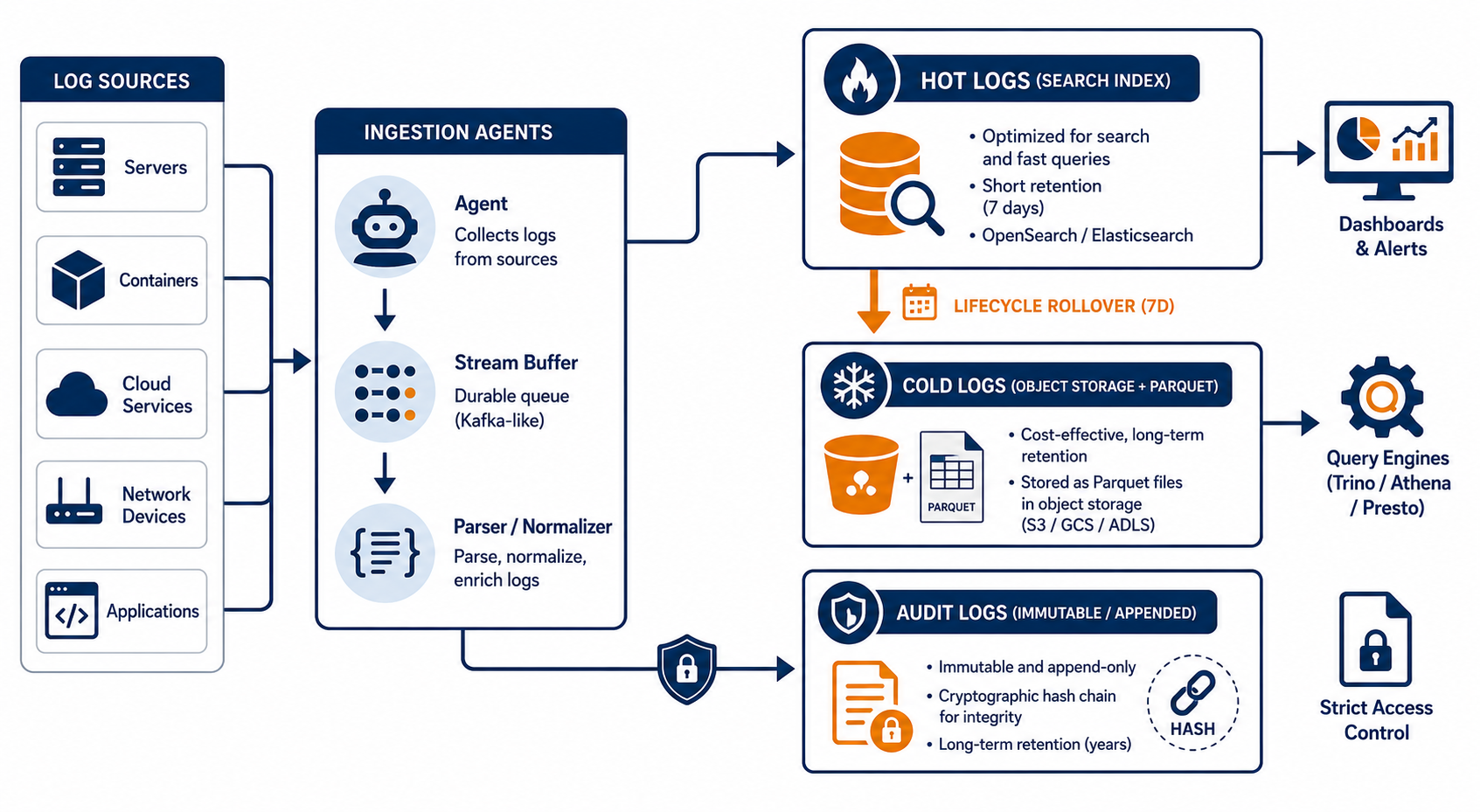
This shows how operational logs flow from ingestion into hot storage, then transition to cold storage, while audit logs go to a protected immutable tier in parallel.
Hot logs: optimize for “minutes,” not “forever”
Hot logs exist for the loop you actually run every day: detect, debug, confirm. That means your hot tier must optimize for low-latency reads and fast aggregations over a short retention window.
Your hot tier usually looks like a search and analytics system with indexing. That gives you fast queries, but it also forces you to pay for indexing structures and frequent write amplification. If you keep long retention in hot storage, you pay the “index tax” for years.
So treat hot logs like a cache with a contract:
- You keep them long enough to cover your operational debugging window (hours to days).
- You support your primary workflows: dashboards, alert correlation, and incident investigations that happen quickly.
- You accept that older logs will move and might not support the exact same query patterns.
Two practical design choices matter here.
First: decide your rollover trigger based on time and volume, not “index size at the end of the month.” If you rollover on time only, big services can spike costs. If you rollover on volume only, you can end up with uneven retention across services. You want a consistent operational window per tenant or service class.
Second: define what “queryable” means for hot logs. If your engineers rely on free-text search, keep that capability hot. If they rely on structured fields and aggregations, ensure your schema and enrichment stay stable. If you don’t, you’ll end up with “we can query it” but not “we can answer the question.”
Cold logs: cheap retention without pretending they are hot
Cold logs are where you put data that you must retain and occasionally investigate, but you do not query every minute. Cold storage is where you stop paying the index tax and start paying per-GB efficiently.
In practice, cold logs usually land in object storage in a columnar format like Parquet, partitioned by time and service (and sometimes tenant). Then you query them with a separate query engine that can scan partitions and filter using metadata.
The trade-off is simple: cold queries cost you latency. That’s okay because cold queries are not your primary workflow. They are for “show me what happened last month” and “prove what changed during the incident window.”
If you build cold storage correctly, you also avoid another common trap: dumping raw JSON blobs into object storage and hoping you can query them later. That turns cold queries into expensive full scans and forces you back toward hot systems.
Most teams get this wrong by skipping schema and partition strategy. They store everything as unstructured text, then wonder why “cold investigations” take 30 minutes and cost more than the hot tier would have.
Your cold tier should have:
- a predictable partitioning scheme,
- consistent field extraction,
- and a query plan that can prune partitions.
If you need to keep cold queries fast enough for incident response, you can keep a small “warm” window or maintain a lightweight index for the cold layer. But don’t pretend you can make cold behave like hot without paying for it somewhere.
Audit logs: separate path, stronger guarantees, stricter access
Audit logs are not “just logs with longer retention.” They record security and administrative actions: who did what, when, and what changed.
The key requirement is tamper evidence. Audit logs must survive operator mistakes and malicious attempts. That means your architecture needs a protected write path, strict read permissions, and an immutability model.
You have two common implementation patterns.
One: write audit events directly into a protected immutable tier. This reduces the chance someone edits or deletes audit records in the normal logging lifecycle.
Two: write audit events into hot for immediate operational visibility, but also persist them into an immutable audit tier in parallel. This keeps incident debugging fast while still meeting audit integrity requirements.
Either way, you should treat audit logs as a compliance surface, not an observability convenience. That affects everything from access control to retention enforcement.
A good litmus test: if an auditor asks, “Can you prove this record wasn’t modified after the fact?” your system should answer with evidence, not a story.
Also, separate audit log storage from operational log storage. If you keep them in the same pipeline with the same lifecycle policies, you will eventually delete something you shouldn’t, or you will apply a retention rule that doesn’t satisfy audit requirements.
Cost and performance: what you measure before you build
Let’s talk numbers, because “it’ll be cheaper” is not a plan.
Hot storage systems typically charge you for both storage and indexing overhead. Cold object storage charges you mainly for storage, and query costs come from how much data you scan and how often you run queries. Audit logs add integrity mechanisms and restricted access workflows, which also cost something.
The simplest way to prevent surprises is to measure your log access distribution and retention needs before you pick tools.
You only need a few metrics: 1) ingestion rate by service, 2) query frequency by time window (last 1 hour, last 24 hours, last 30 days), 3) compliance retention requirements for audit events.
Then you can model a tiering policy. For example, if 80% of queries are within 24 hours, you keep 24 hours in hot and move the rest. If audit events are tiny in volume but must live for years, you route them immediately to the protected tier and stop thinking about hot retention for them.
One more cost reality: egress. If your cold queries run from a different network or region, you can accidentally pay large bandwidth bills. That is why cold storage and query engines should be co-located as much as your architecture allows.
If you want a concrete storage baseline, IBEE Object Storage is S3-compatible, so your existing AWS tooling and SDKs can write cold log files without code changes. The pricing model also makes cost predictable: storage at ₹1.5/GB/month and egress at ₹2/GB. That predictability matters when you start partitioning and archiving aggressively.
Implementation details that keep this from breaking in production
Tiering fails when the pipeline stops being deterministic. You need rules that are enforced, not “best effort.”
Here’s what you should implement in your logging pipeline.
First, classify events at ingestion time. Decide whether an event is operational, audit, or both. Don’t rely on downstream guessing. If you can’t classify reliably, you will either miss audit coverage or you will pollute audit tier with noisy operational logs.
Second, enforce lifecycle policies per tier. Hot retention should be automated. Cold retention should be automated. Audit retention should be locked down with immutability controls. If any of these depend on manual cleanup, you will fail at scale.
Third, keep your schema stable across tiers. Hot and cold should agree on the fields you use for filtering. If you change field names or types, your cold query engine will quietly return wrong results or empty sets during an incident, which is the worst kind of failure.
Fourth, build a replay or backfill path. When you fix parsing bugs, you need to reprocess logs from cold storage. If you never design for replay, you will accept incorrect data forever or spend weeks rebuilding pipelines.
Real-world example from one enterprise I worked with: they used one hot index for everything, then “archived” by exporting raw JSON to object storage without partitioning. During a security incident, the audit team could not locate the admin action logs fast enough. The team ended up re-ingesting and re-indexing under pressure. That is exactly what tiered design prevents.
What to do today: write your tiering contract
Do this before you touch infrastructure. Write a one-page logging tiering contract with three sections: Hot, Cold, Audit.
1) Hot: define the exact retention window and the top 5 queries engineers run. 2) Cold: define the partition keys, retention duration, and the query engine you will use for investigations. 3) Audit: define the immutable write path, retention duration, and who can read it.
Then map your current pipeline to that contract. Wherever you can’t prove a requirement, you don’t “have logging.” You have hope.