Most teams don’t pick the wrong component because they don’t know what it is. They pick it because it’s the first thing that sounds like “front door.” Then they spend weeks untangling responsibilities that should never have been mixed.
The migration took six weeks. Three of them were spent undoing a decision made in the first hour: the team used an API gateway as a general-purpose load balancer, then bolted auth and rate limits onto the reverse proxy “because it was already there.” The result was predictable. Debugging turned into archaeology. Latency spikes became policy bugs. Failures looked like “infrastructure issues” even when the real cause was a gateway policy misconfiguration.
You don’t need more tools. You need the right mental model for what each layer actually does.
The uncomfortable truth: you’re not choosing tech, you’re choosing responsibilities
Here’s the mistake most teams get this wrong: they choose based on where traffic terminates, not based on what guarantees they need.
If you only think in terms of “who sits in front,” you’ll end up with one layer doing everything. That works until you hit any of these realities: per-consumer quotas, API versioning, sticky sessions, health check behavior, or TLS termination requirements across environments.
So treat the decision like this: write down the responsibilities you need, then map them to the layer that owns them.
Reverse proxy is the general front door for HTTP routing and edge behaviors. Load balancer is the traffic distributor for availability and scaling. API gateway is the policy enforcement and API lifecycle layer for API traffic.
Yes, overlap exists in real products. Many systems can do multiple jobs. But overlap doesn’t mean you should use one component as a substitute for another. Your future self will pay for today’s shortcuts.
A simple way to decide: map your requirements to the layer that owns them
You can reason about this without vendor docs if you ask three questions.
First: do you need API-specific identity and governance? That means API keys or OAuth/JWT validation, authorization rules, rate limiting, quotas, request and response transformations, API versioning, and per-route observability. If yes, that’s API gateway territory.
Second: do you need availability and scaling across instances with health checks and load distribution? That means the system must continuously decide which backend instances should receive traffic, remove unhealthy ones, and handle connection behavior. If yes, that’s load balancer territory.
Third: do you need general routing and edge HTTP features like TLS termination, host or path routing, header normalization, and sometimes caching? If yes, that’s reverse proxy territory.
Most architectures don’t pick only one. They stack them because each layer is responsible for a different kind of correctness.
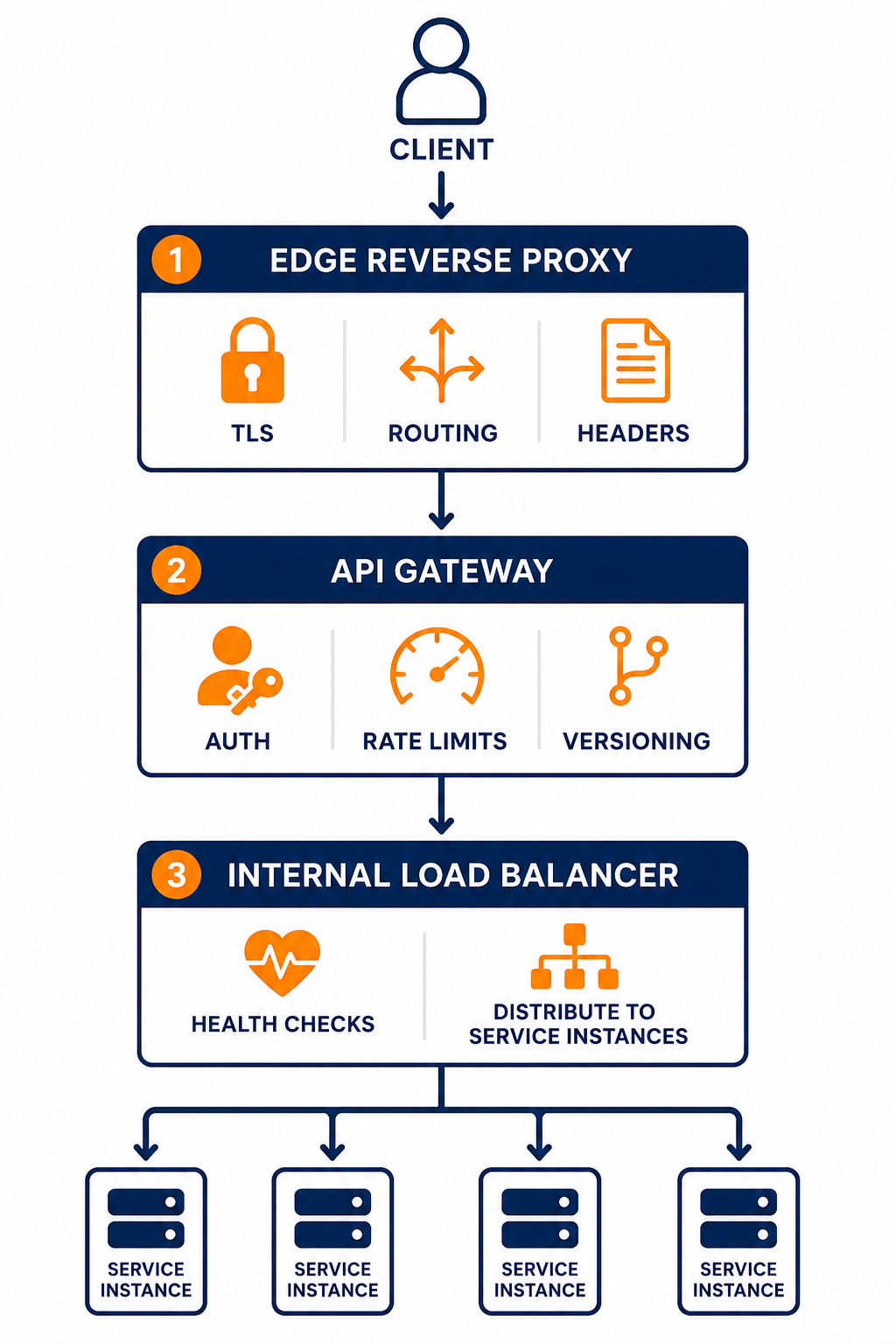
This diagram shows the typical layered ownership of TLS, API policy, and instance scaling.
What each component is best at (and what it will punish you for)
Reverse proxy is best when you want a flexible edge that forwards requests intelligently. It owns routing rules, TLS termination, header rewriting, and often caching or compression. It can also provide basic security controls, but don’t confuse “can” with “should.”
The punishment comes when you try to use it as a governance layer. Reverse proxies are not great at expressing API lifecycle policies in a way that maps cleanly to consumers, plans, and versioned contracts. You can implement auth and rate limiting, but you’ll end up with policy sprawl and inconsistent analytics.
Load balancer is best when you want predictable traffic distribution. It owns health checks, backend pools, connection handling, and scaling behavior. It exists to keep your app reachable and fast under failure and growth.
The punishment comes when you need per-consumer API rules. Load balancers can do some L7 routing depending on the product, but they typically don’t model API concepts like consumers, quotas, and route-level transformations. If you force it, your “availability layer” becomes a half-baked API policy engine.
API gateway is best when you want API governance you can operate. It owns authentication, authorization, rate limiting and quotas, request and response transformation, API versioning, and developer-facing observability. It also gives you a place to enforce policy consistently across routes.
The punishment comes when you use it as the primary scaling and routing mechanism. When you overload the gateway with generic traffic forwarding and instance selection, you increase coupling. You also risk turning the gateway into a bottleneck because policy evaluation becomes part of your critical path for every request.
A quick mapping you can use in design reviews
If you’re in a design review and someone says “we’ll just use the gateway for everything,” stop them. Ask what kind of correctness they’re aiming for.
You want TLS and edge routing? Use a reverse proxy or edge load balancer. You want health checks and instance distribution? Use a load balancer. You want API identity, quotas, and versioned behavior? Use an API gateway.
Then decide where each responsibility lives. For example, you can terminate TLS at the edge reverse proxy, enforce API auth and rate limits at the API gateway, and distribute to service instances using an internal load balancer.
One real-world company example: Netflix famously invested in internal API gateway-like patterns for consistent routing and policy enforcement across microservices. The key lesson for you is not the vendor or product. It’s the boundary: they kept API governance separate from instance scaling so teams could evolve independently.
Also, watch for the “sticky session trap.” If your app requires session affinity, you might need it at the load balancer layer. If you implement affinity at the gateway, you can accidentally create a stateful gateway dependency that makes scaling and rollbacks harder than they need to be.
How to structure it in practice (without creating a policy maze)
Here’s the practical layered approach most teams converge on once they stop improvising:
- Use an edge reverse proxy or edge load balancer to handle TLS termination and basic routing from the internet into your network.
- Use the API gateway to enforce identity and API policies like rate limiting, authorization, and API versioning.
- Use an internal load balancer to distribute requests across service instances with health checks and autoscaling integration.
This separation matters because it keeps failure modes understandable. When your service is slow, you can tell whether the bottleneck is policy evaluation, connection distribution, or backend execution.
It also keeps ownership clean. Network teams can own edge routing and TLS. Platform teams can own API policy templates. Service teams can own their own scaling and health endpoints. That division reduces the “everyone touches everything” problem that turns incident response into blame games.
If you’re running on Kubernetes, don’t ignore the reality that ingress controllers, service meshes, and gateways can overlap. Kubernetes Ingress can look like routing. Service mesh can look like a proxy. That’s exactly why teams get this wrong. They assume “we already have a proxy” means they don’t need to decide where policy and scaling responsibilities should live.
If you want a concrete, low-drama starting point, keep the gateway focused on API concerns and let the load balancer focus on distributing traffic to healthy instances. Then add reverse proxy features only where they reduce edge complexity, like TLS termination and header normalization.
The decision checklist you can use today
Most teams don’t need a new architecture. They need a sharper boundary.
Answer these questions and you’ll know what to deploy where:
- Do you need per-consumer auth and quotas? If yes, you need an API gateway.
- Do you need health checks and instance distribution? If yes, you need a load balancer.
- Do you need TLS termination and HTTP routing and header rewriting? If yes, you need a reverse proxy at the edge.
- Are you trying to use one component to handle all three responsibilities? If yes, split the responsibilities before you build.
If you want to make this operational, standardize it in your platform layer. For teams standardizing Kubernetes ingress and API traffic patterns, IBEE’s Cloud Load Balancer and Cloud Firewall can sit at the boundary while your API gateway handles policy, keeping the edge and governance responsibilities clean.
One action to take today
Pick one existing endpoint in your system and trace it end to end. Write down which layer enforces each responsibility: TLS termination, routing, auth, rate limiting, and backend selection. If any single component owns two or more of those responsibilities when it shouldn’t, change the design on paper first, then implement the split in the next deploy.