

Most teams don’t fail because they picked the “wrong” CDN or the “wrong” encoder. They fail because they treat video like a single file. Then every playback request turns into a scavenger hunt across storage, cache, and permissions that were never designed for time-sliced assets.
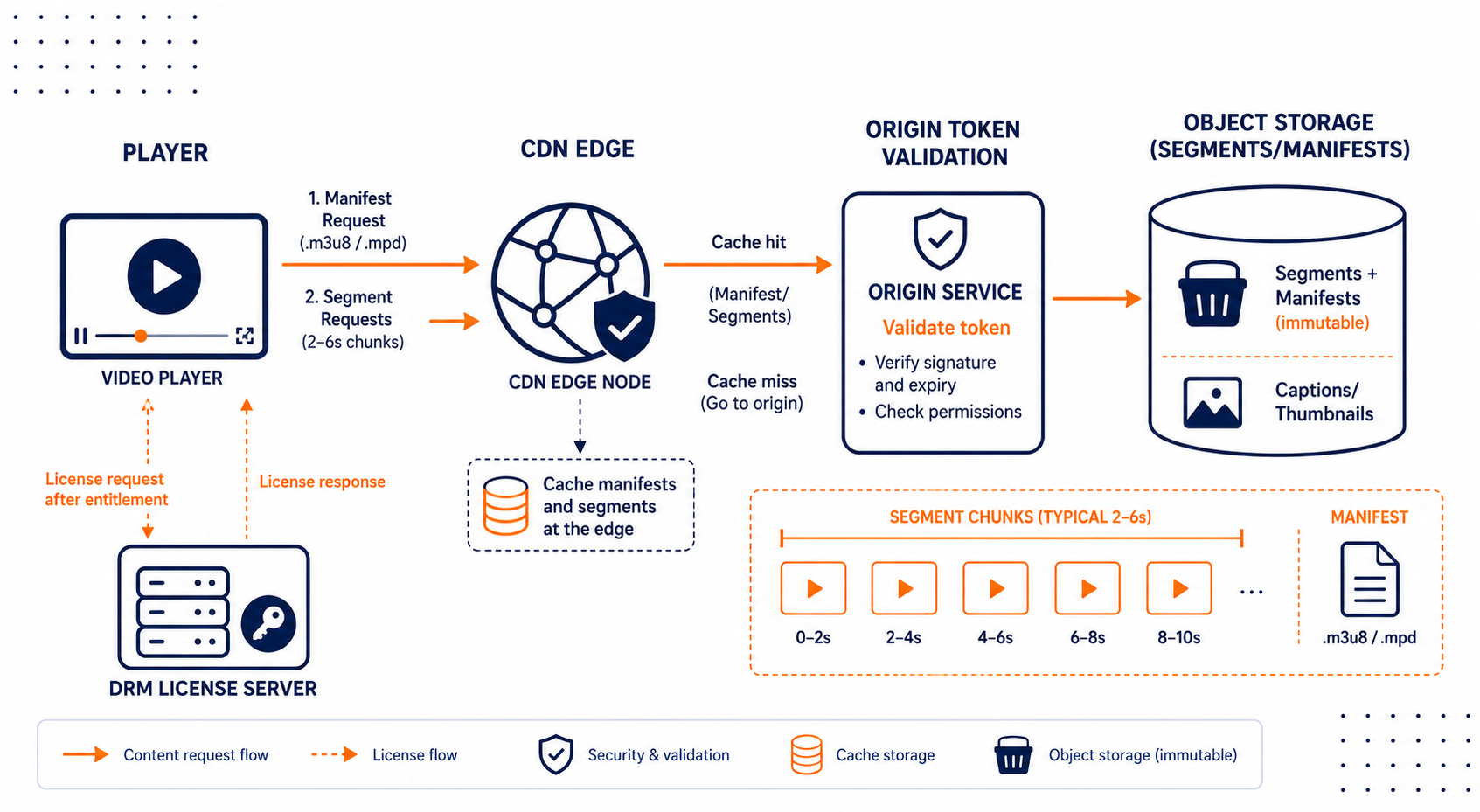
The uncomfortable truth: you only get predictable performance and cost when you design around the actual request pattern. In ABR streaming, your application does not read “a video.” It reads manifests and then hammers segment URLs for minutes at a time. If your storage and caching strategy assumes the opposite, you’ll spend months firefighting 403s, cache misses, and runaway egress bills.
The real problem: you’re storing access patterns, not videos
You’re storing a pipeline of outputs per title, not a blob. For each rendition (say 360p, 720p, 1080p), you produce:
You publish manifests (HLS .m3u8 or DASH .mpd) that point to segments. The player then requests those segments repeatedly, often in parallel, and it retries aggressively when something fails. That means your storage must satisfy two constraints at the same time:
First, low-latency origin retrieval for cache misses. Second, deterministic caching behavior so the CDN can do its job without thrashing.
Here’s the part most teams get wrong. They put “video files” into object storage and call it a day, then they generate manifests with unstable URLs. One day you include volatile query params in segment links. Another day you change naming conventions after a re-encode. Result: CDN cache keys fragment, you get a high miss rate, and your origin starts doing the work your CDN should have handled. You won’t notice until traffic ramps, because staging traffic rarely triggers the worst-case retry loops.
So you need to design for immutability. For VOD, segments should be content-addressed or at least versioned so you can set long cache TTLs. Manifests can update, but segment URLs should not “move under the player.”
How the components should connect (and where to enforce security)
Your reference architecture is simple on paper and strict in practice:
- Object Storage holds encrypted or plain segments, init segments, captions, thumbnails, and manifests.
- CDN caches manifests and segments at the edge.
- Origin services handle token validation, manifest generation or fetch, and access control.
- DRM license server issues decryption keys after entitlement checks.
- Metadata/catalog stores title, chapters, languages, and playback policy.
The tricky part is not the components. It’s the boundaries. If you push entitlement logic into the CDN origin pull for every segment request, you’ll multiply authorization overhead by every viewer and every segment. That’s how you turn a storage problem into a CPU and latency problem.
A better model is:
Manifests and segments remain cacheable wherever possible. You authorize at the request boundary using signed tokens, but you do it in a way that doesn’t destroy caching. For example, you can validate tokens at the manifest request and ensure the returned segment URLs remain valid under the same authorization context. For DRM, you keep media key issuance tightly controlled by the license server, because the player will request keys separately anyway.
On the storage side, you also need atomic publish. If you upload segments and then later upload the manifest, players can fetch a manifest that references missing segments. That creates 404 spikes and forces retries, which inflates bandwidth and origin load. Your publish workflow must treat a rendition publish as a single cutover.
Storage design rules that stop cache misses and re-encoding pain
Once you accept that video is a set of time-sliced assets, the design becomes mechanical. Your job is to make URLs stable, publish atomically, and keep lifecycles sane.
Most teams start with a folder layout like titleId/rendition/segmentIndex. That can work, but only if you lock down three things:
Naming must encode the rendition and the encode version so you never overwrite segments in place. If you overwrite, you invalidate caches and you break “long TTL” assumptions.
Packaging must preserve deterministic segment boundaries. If your encoder settings change and you regenerate segments, you should publish a new encode version rather than trying to “fix” the old one.
Publishing must validate before publish. You need checksum validation and manifest consistency checks, otherwise you ship broken manifests that cause player retry storms.
Now the cost side. You can’t optimize cost by watching total storage alone. Streaming cost is dominated by egress and request patterns. In India, teams often get surprised by how quickly bandwidth dwarfs storage. If your CDN hit rate drops from 95% to 85%, you don’t just lose performance. You pay for it with every missed segment fetch.
A practical strategy is to treat CDN caching as a first-class requirement:
Manifests should have long enough TTLs to avoid origin thundering herds, but short enough to support updates like availability windows or subtitle corrections.
Segments for VOD should be immutable and cacheable for a long time. If you need to correct something, generate a new encode version and shift manifests to point to the new segments.
For live or near-live, you can shorten TTLs, but you still want stable cache keys. Do not include volatile query params unless you truly need them.
DRM and entitlements: don’t break caching with “auth everywhere”
DRM adds another dimension: encrypted segments and a license exchange. The player decrypts locally, but it cannot decrypt without keys. That means your pipeline has two security surfaces:
Media encryption and key delivery. Entitlement checks for both manifest access and license requests.
Most teams get this wrong by trying to gate every segment request with heavy authorization logic at the origin. That kills throughput and makes latency spiky. Segment requests are high-volume and repetitive. You want them to be cheap at the edge.
Instead, structure authorization so that:
Manifest access enforces entitlement in a way that doesn’t randomize URLs. Signed tokens or cookies should be consistent enough for CDN caching.
License requests enforce entitlement at the license server. That’s where you actually need strict per-user checks.
Key rotation and DRM policy live in the DRM layer. Don’t leak that complexity into your storage naming or segment URL structure.
Also, keep auditability. You will need to prove what keys you issued and why a user got access. Log entitlement decisions and license issuance events. Store logs in a way that supports later forensic queries, not in a way that makes you grep production.
Operational workflows: ingest to publish without “half-ready” content
Your pipeline should look like this in practice, not as a diagram:
- Ingest and validate the source file.
- Normalize audio loudness and video properties.
- Encode the full ladder of renditions.
- Segment and package into CMAF or the formats you standardize on.
- Encrypt segments if DRM is enabled.
- Generate manifests and captions.
- Run integrity checks: segment completeness, manifest references, checksum verification.
- Upload all assets under an immutable encode version.
- Atomically publish by switching manifest pointers or availability flags.
- Monitor playback metrics and error rates, then iterate encode settings.
The reason this matters is failure mode. If you publish manifests early, players will request missing segments and retry. That creates load amplification: more retries means more origin reads means more cache misses, which means more failures. It’s a vicious loop.
If you use S3-compatible object storage, you can keep the workflow simple: upload segments and manifests, then flip a catalog flag. The storage layer should support high throughput for large objects and stable durability so you never lose segments mid-session. For OTT and Edtech, object storage plus a CDN is the default for a reason: it’s operationally boring, which is what you want when traffic spikes.
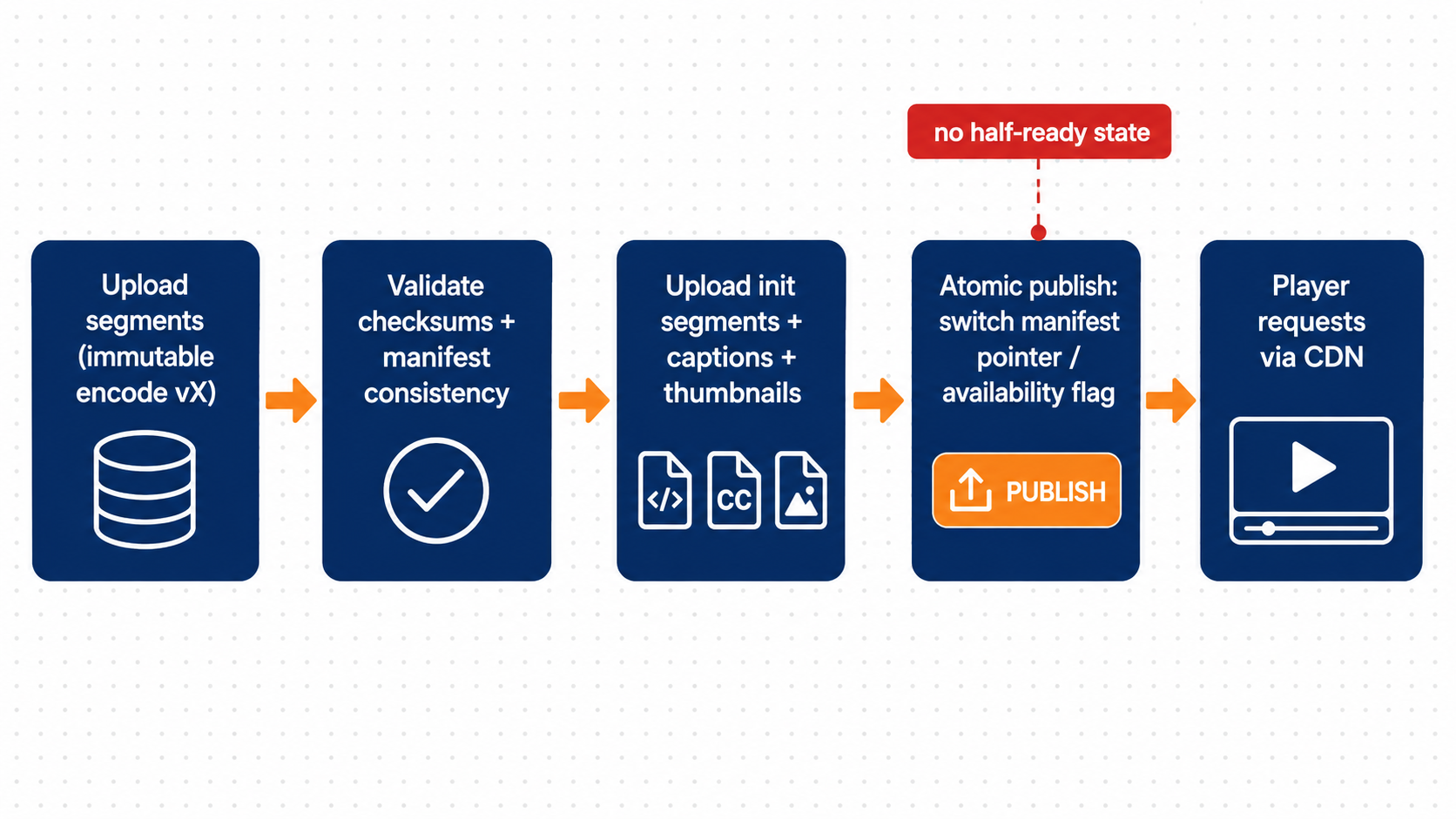
Atomic publishing ensures players never receive manifests that reference missing segments.
Your action plan for today
Pick one title (or one content type) and audit the request pattern end to end. Specifically, trace a single playback session and answer these questions:
Are segment URLs immutable across re-encodes? Do manifests ever reference segments that are not yet available? Do you include volatile query params in segment links that should be cacheable? Where do you enforce entitlement, and is it happening on every segment request?
Then fix the worst offender first. If you find unstable URLs, lock down naming and versioning, republish, and enforce long CDN TTLs for segments. That one change usually improves both performance and cost, because it restores the CDN’s ability to absorb the traffic spike instead of your origin doing the work.





