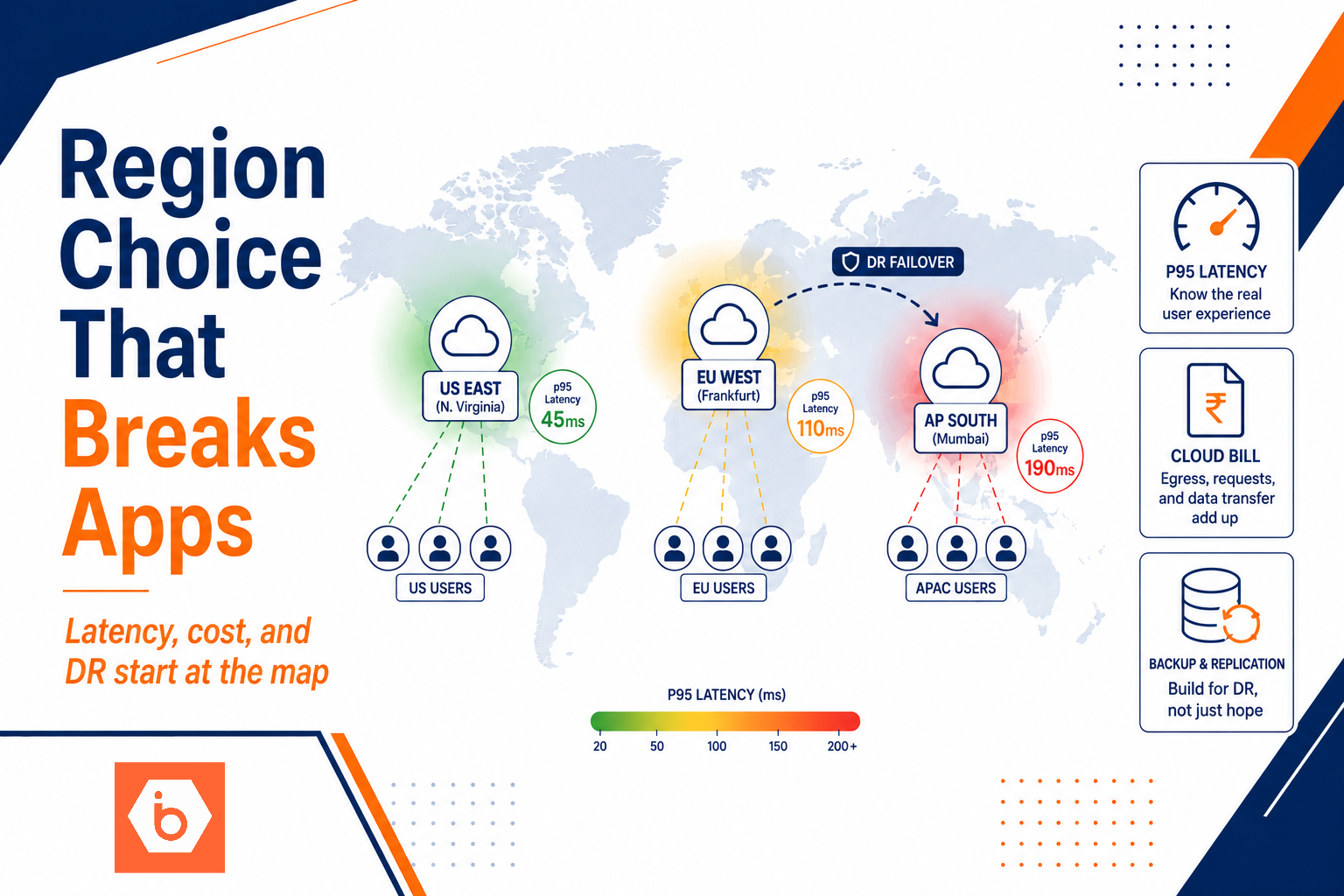

Most teams don’t “choose a region.” They pick whatever their first engineer used last time, whatever the default console suggests, or whatever is easiest to provision. Then the product ships. And suddenly your p95 latency is 2x worse for half your users, your cloud bill grows faster than traffic, and your DR plan turns into a spreadsheet exercise.
The uncomfortable truth: region choice is an architectural decision. You can’t fix it later with a caching layer or a “quick” DNS update.
The failure mode you actually see in production
Here’s what typically happens after you pick a region “for convenience.”
You deploy compute in Region A, but your stateful dependencies land in Region B (database, object storage, search, auth, logging pipeline, backups). Even if each hop is “fast,” your end-to-end request includes round trips to the slowest dependency chain. Interactive workloads feel it immediately: login, checkout, dashboards, AI inference, anything with a tight feedback loop.
Most teams get this wrong in a very specific way. They benchmark the API server locally, then forget that the API server does not own the real work. The database does. The queue does. The cache might help, but only for the hot path. If your database is 80 ms away and your request needs 6 round trips, you just added roughly a full second of tail latency before you even talk about CPU.
Reliability gets worse too, but in a different way. Multi-AZ protects you from an Availability Zone outage, not a region-wide event. Teams often say “we’re HA” because they spread across AZs. Then a region outage happens and their “HA” system is down for hours because failover is not tested, replication lag is unknown, and session handling is brittle.
And cost? Region choice quietly multiplies cost through egress, inter-region traffic, replication, and the pricing availability of services. Compute that seemed “cheap” in one region becomes expensive once you pay to move data around every request.
How region choice warps latency, cost, and reliability
Let’s separate what developers think matters from what actually dominates.
Latency is shaped by distance and dependency order. It is not just the user to the API server. It is the user to the API server, then API server to database, then database back to API server, then API server to storage or cache, then back again. If your app tier sits near users but your database sits far away, your p95 and p99 will track database round trips, not your web server performance.
Cost is a chain reaction. A region that is “near” users might increase your egress if your storage or CDN origin is elsewhere. Another region might have cheaper compute but force inter-region replication for backups, logs, and analytics. If you run microservices across regions, the inter-service calls become a recurring bill. Small request payloads still add up at scale because you pay per gigabyte transferred, not per job completed.
Reliability is about blast radius and recovery mechanics. Region choice decides what your failure domain looks like. If your primary and secondary are in the same region, you’re not protecting against region loss. If you go multi-region without a plan for RTO and RPO, you’re just building a faster way to fail. Failover complexity matters: DNS cutover, connection draining, state migration, and cache warmup can add hours if you never rehearsed it.
There is also a governance dimension. If you have regulated data, you may not be allowed to store it outside a jurisdiction. In those cases region choice is not a performance decision, it is a compliance constraint. You can’t “optimize” your way out of a legal requirement after the fact.
Region choice meets Kubernetes and CI/CD (where teams break things)
Now you’re probably thinking: “We run Kubernetes. We can deploy anywhere. We’ll fix it with manifests.” That’s where teams get sloppy.
In Kubernetes, region choice impacts more than where pods run. It impacts:
State placement. StatefulSets, databases, caches, and persistent volumes are where region decisions become permanent. If your Block Storage and backups live in a different region than your workload, you’ve created a cross-region dependency. That dependency will show up in tail latency and cost.
Service discovery and routing. If you rely on internal DNS names, load balancers, and ingress controllers, you need to confirm how traffic routes across regions. Geo-routing can help, but only if your stateful dependencies match the routing strategy.
Observability. Traces and logs must be correlated across regions. Otherwise you’ll “solve” latency by guessing, and guessing costs time and money. You need consistent instrumentation and a region-aware logging pipeline.
CI/CD environment parity. Your pipeline might build and deploy the same container image everywhere, but region-specific differences still creep in: service availability, quotas, IAM policies, network paths, and secret distribution. If your staging region doesn’t match your production region, you will discover region-specific failures the hard way.
Here’s a practical way to think about it: region choice is a constraint on your architecture graph. You can move compute pods easily. You cannot move the physics of network round trips and you cannot move the compliance boundary of data residency without re-architecting state.
And if you are running CI/CD with artifacts and caches, region choice affects that too. Your pipeline might upload artifacts to object storage for each deploy. If the storage region differs from your build execution region and your runner pulls from another region, you pay latency and egress repeatedly. Your “deployment speed” becomes a storage and networking story.
A quick decision framework that won’t lie to you
You need a repeatable method. Not a one-time gut feel.
- Write your dependency graph. For every request type, list the ordered dependencies: API to DB, API to cache, API to object storage, API to queue, and any third-party calls. Put the “stateful” dependencies in bold in your notes.
- Measure region-to-region round trips, not server CPU. Run a synthetic trace that includes the full dependency chain. Track p95 and p99. CPU metrics will distract you because they do not include network and serialization time.
- Decide your primary performance boundary. If you serve users in India and your primary dependency is in the US, you will pay for it forever. If you use a CDN or edge for static content, that helps for assets, not for database-backed APIs.
- Define RTO and RPO before you pick multi-region. If your business requires failover in minutes, you need active-active or warmed standby with tested cutover. If you can tolerate hours, you can pick simpler strategies. Don’t choose multi-region because it sounds mature.
- Check data residency constraints early. If your data must stay in-country, treat region choice as a compliance requirement. Your architecture should assume the constraint, not fight it later.
- Model cost using transfer paths. Include egress and inter-region traffic. A region that reduces latency might increase egress if it forces more cross-region reads and writes. Most teams get this wrong by estimating storage and compute only, then ignoring request-driven transfer.
One more blunt point: if your architecture still works when you “move compute,” you’re not done. The question is whether your architecture stays correct and fast when you move the dependency chain.
Region choice and storage: the hidden multiplier
Storage is where region decisions become expensive quickly. Object storage patterns are often overlooked because developers treat storage as “just files.” But your application reads and writes objects constantly, and every access can trigger network transfer.
If your Object Storage bucket sits in a different region than your Kubernetes workloads, you introduce cross-region fetches and higher egress. If you replicate data across regions for DR, you multiply storage and transfer. If you keep backups in another region, your restore path includes additional network cost and time.
Object storage also affects CI/CD. Uploading build artifacts, caching dependencies, and storing logs or media assets can create a steady stream of traffic between regions. If you pick a region that’s “fine for compute” but mismatched for storage access patterns, you’ll pay for it every deploy and every user request.
This is where teams should stop thinking in terms of “developer convenience” and start thinking in terms of transfer paths and residency boundaries. If you are building for Indian customers and you keep data in India, you avoid a lot of cross-border egress pain. And if you are comparing S3-compatible options, you should compare egress cost because that is what dominates at scale for API-backed and media-heavy products. Region choice is not only where the servers run. It is where your bytes travel.
One action you can take today
Pick one critical user journey and force it through a region stress test.
Run a synthetic trace from a realistic client location to your service, and include every dependency hop. Do it twice: once with your current region layout, and once with a hypothetical “dependency moved to the other region” layout. You will see the truth in the numbers: p95 latency inflation and cost multipliers from egress and inter-region calls.
If you want a concrete next step for planning, inventory your stateful dependencies and write down which region each one lives in. Then decide whether your region strategy matches your access patterns. If it doesn’t, fix the architecture now, not after your first big load test.
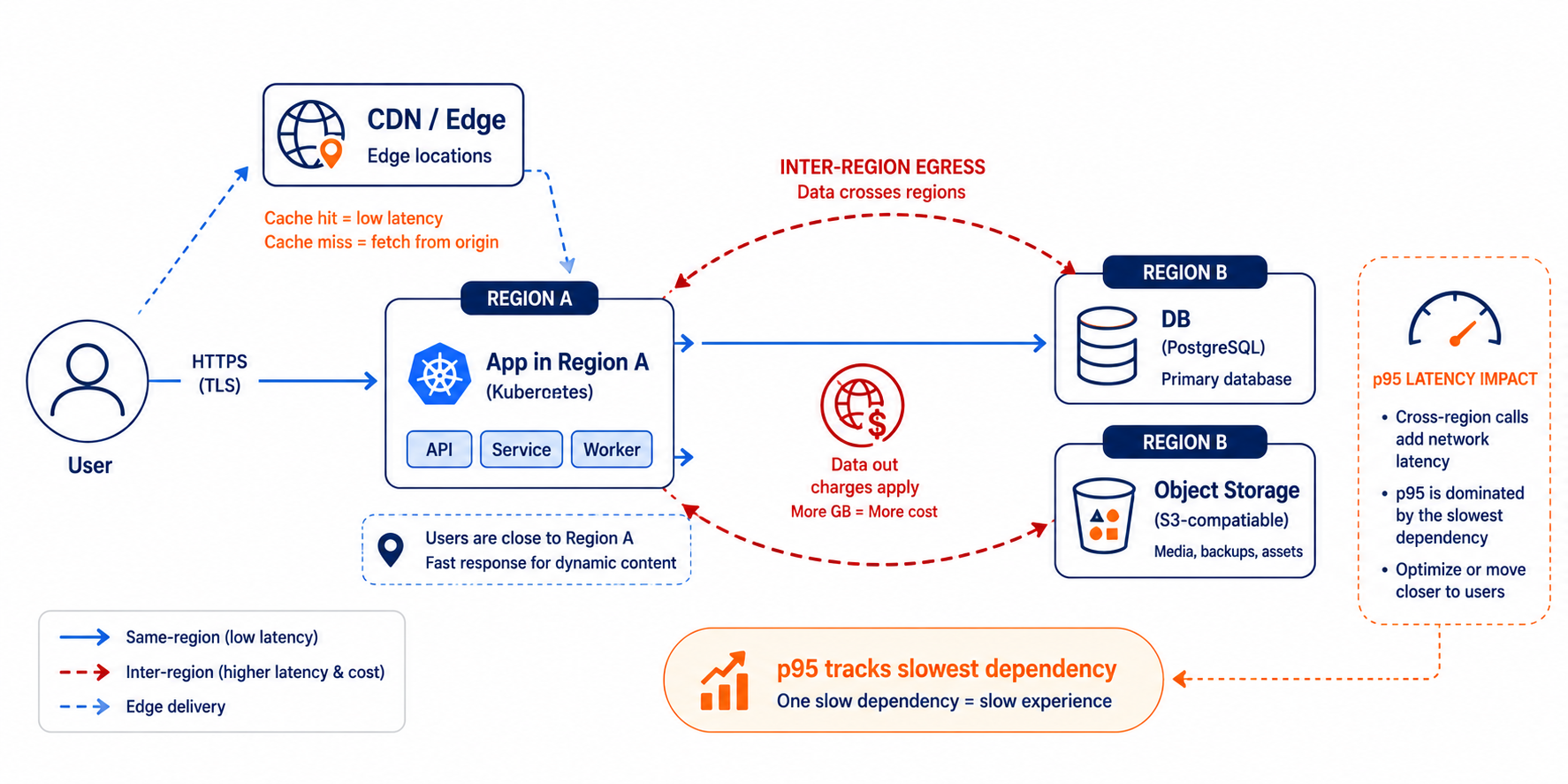
Shows how a single request fans out across regions and where latency and egress get introduced.
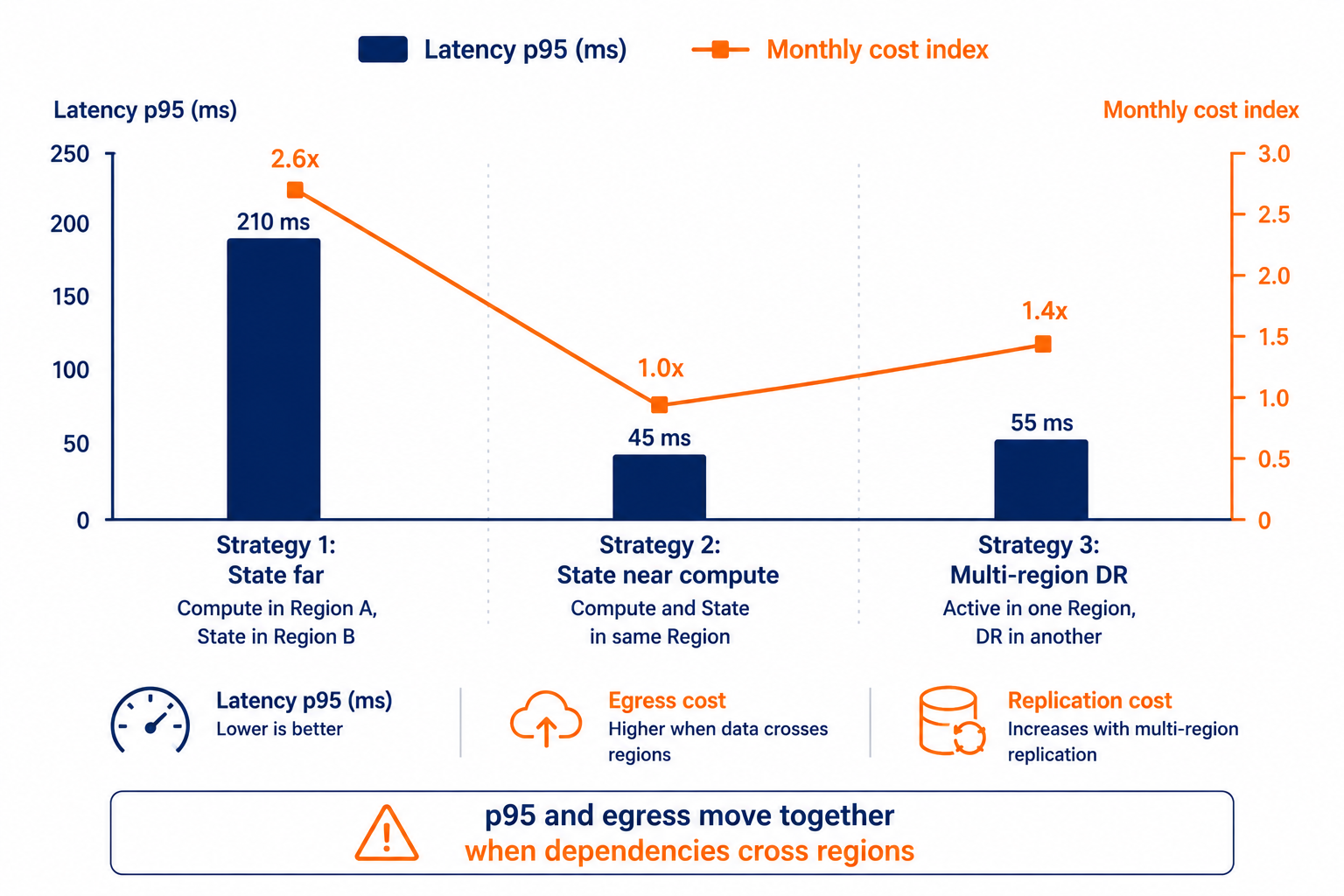
Illustrates how moving state closer reduces latency but can change egress and replication costs.