The Staging Environment Lie
Every startup has a staging environment. Very few have a staging environment that actually catches the bugs that matter.
The standard startup staging setup is a smaller compute instance, a shared database with a subset of production data, and either a separate storage bucket on the same cloud provider or, most expensively, no staging storage at all, with tests pointing at production buckets with a staging prefix.
This setup catches obvious application logic errors. It does not catch the bugs that only appear under real data shapes, at real data volumes, with real infrastructure latency. It does not catch the bug where a file upload that works for a 500 KB test image fails silently for a 45 MB user video. It does not catch the performance regression that only manifests when querying a database with 2 million rows rather than the 500 rows in the staging database. We have seen teams spend two to three days debugging a production incident that a properly configured staging environment would have surfaced in the first test run.
The gap between what staging catches and what production reveals is not a testing problem. It is a parity problem.
Why Environment Parity Is Hard for Startups
The reason most startup staging environments are low-fidelity is cost. Running a second, production-equivalent environment costs roughly as much as production itself. For a pre-Series A startup, doubling the infrastructure bill to have a better staging environment is not a trade-off most teams will make.
The right answer is not to spend double but to be deliberate about which parts of the environment need high parity and which can be safely cheapened. Not all environment differences create bugs. Only specific differences in specific parts of the stack produce production failures that staging should have caught.

Parity decisions are about risk, not perfection.
What Actually Needs to Match
Storage provider and API is the first requirement. If staging uses LocalStack, MinIO, or a local S3 emulator while production uses IBEE or AWS S3, you will eventually see bugs caused by subtle differences in how those implementations handle edge cases: multipart upload completion, presigned URL expiry, error response formats, metadata handling. Use the same S3-compatible provider in staging as in production. Because IBEE has no minimum commitment and charges per actual use, a staging bucket on IBEE costs essentially nothing for low-volume test workloads. The parity value is high; the cost is near-zero.
Configuration structure is the second requirement. Environment variables in staging must have the same names and structure as in production. The value differs; the key names must not. A staging environment where STORAGEBUCKET is set and production uses S3BUCKET_NAME will eventually cause a deployment where the wrong variable name makes it into a production config.
Data shapes matter more than data volume. Staging databases do not need 10 million rows. They do need representative data shapes: the edge cases, the unusual characters in text fields, the large nested JSON structures, the records with null values in unexpected columns. Staging populated only with clean test-fixture data will not catch the bugs caused by real-world data messiness.
Dependency versions are the fourth area that must match. Node.js 18 in staging and Node.js 20 in production, or PostgreSQL 14 in staging and PostgreSQL 15 in production: these gaps are where subtle behavioural differences live. Pin dependency versions across environments and update them together.
What Can Safely Be Cheapened
Compute size can be reduced without significant risk. Staging compute can be half or a quarter of production size. Most bugs are not caused by being on a smaller instance type. Performance testing is a separate concern from functional testing.
Redundancy is not needed in staging. Production has multi-AZ database replication and multiple application instances. Staging can run a single instance of everything. Failover and replication bugs are tested in disaster recovery drills, not in routine staging deployments.
Data volume, as noted above, can be significantly reduced. A staging database with 50,000 representative records catches more bugs than one with 100 clean fixtures or one with a full production copy that is expensive to maintain and is never refreshed.
Monitoring and alerting can be minimal. Staging does not need the full production observability stack. Basic logging is enough for a staging environment.
The Storage Parity Argument in Detail
Storage is the place where environment parity most often breaks down and where the consequences of that breakdown are most expensive to debug.
The three failure modes from storage environment divergence are bugs in upload handling that only appear with the real provider's error responses, performance characteristics that differ enough to expose timeout bugs, and security misconfigurations that pass in a permissive local emulator but fail against a real provider with strict access controls. Storage divergence bugs are also among the hardest to diagnose because they surface as intermittent failures rather than consistent ones — the emulator and the real provider agree on the happy path and diverge only at the edges.
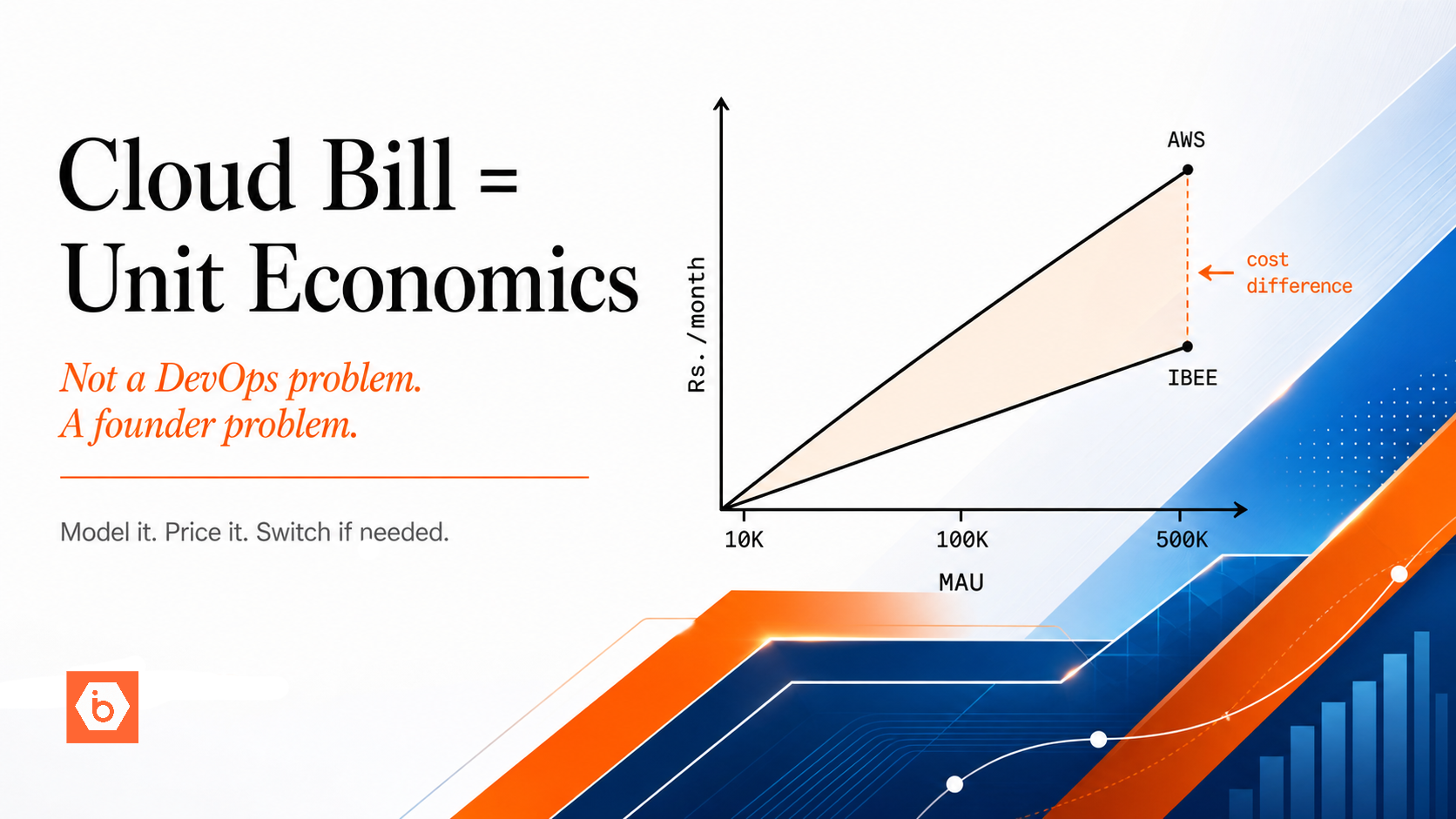
The solution is to use the same storage provider in staging as in production, with separate buckets and separate credentials. For startups using IBEE in production, the staging bucket on IBEE costs Rs.1.50/GB-month ($0.016/GB-month) for whatever test data you store, typically a few gigabytes, which amounts to a few rupees per month. All USD equivalents in this article use a conversion rate of Rs.94.91 per dollar as of May 2026. The cost of storage parity is near-zero. The value of catching storage-related bugs in staging before they reach production is measurable in every outage you avoid.
The recommended structure is three buckets: myapp-prod, myapp-staging, and myapp-dev. Same provider, same API, same configuration structure. Different credentials for each environment, so a misconfiguration in development cannot accidentally write to or read from production.
Environment Configuration Management
The practical implementation of environment parity is a configuration management discipline. Every environment-specific value, database connection strings, storage credentials, API keys, feature flags, should live in a dedicated configuration store and follow the same schema across all environments.
A configuration schema document, even a simple README, that lists every environment variable your application reads, what it does, and its expected format in each environment is worth writing once and maintaining. It eliminates the class of production bugs caused by adding a new environment variable in development and forgetting to add it to staging and production.
For storage specifically, STORAGEENDPOINT, STORAGEACCESSKEY, STORAGESECRETKEY, STORAGEBUCKET, and STORAGE_REGION should be consistent variable names across all environments. The values differ; the names do not.
The Deployment Pipeline Implication
High staging-production parity is only valuable if staging is actually in the deployment path: if the code that passes staging is the code that goes to production. This sounds obvious. At many startups it is not enforced.
The pattern to avoid is one where engineers merge to main, production deploys from main, staging deploys from main separately, but staging failures do not block production deployments. This gives you the cost of maintaining a staging environment with none of the bug-catching value.
The pattern to build is one where staging is a mandatory gate in the deployment pipeline. A failing staging deployment blocks the production deployment. This requires staging to be reliable enough to run automatically on every merge, which brings you back to the parity question. A flaky staging environment that fails for infrastructure reasons rather than code reasons trains engineers to ignore staging failures. High parity staging that only fails when code is genuinely broken is the kind worth making a deployment gate.
IBEE for Non-Production Environments
IBEE's permanent free tier, 25 GB storage and 50 GB egress per month with no expiry and no payment method required, covers most startup development environments entirely. Staging environments with low-volume test workloads fit within a few rupees of monthly cost. The same S3 API, the same error responses, the same authentication model as production.
For startups running production on IBEE, using IBEE for staging and development is the easiest way to achieve storage layer parity at near-zero incremental cost.