RTO and RPO: The Two Numbers That Define Your DR Strategy
Before choosing a DR architecture, a business must answer two questions with specific numbers.
The Recovery Time Objective, or RTO, is how long the business can operate without the affected system. An e-commerce platform that loses its order management system has an RTO measured in hours. A payment processing platform has an RTO measured in minutes. A content archive has an RTO measured in days. The RTO determines how much to invest in standby infrastructure and recovery automation.
The Recovery Point Objective, or RPO, is how much data the business can afford to lose. An RPO of zero means no data loss is acceptable and every transaction must be committed to a secondary location before it is confirmed to the user. An RPO of one hour means the business can recover from a failure by restoring state from up to one hour ago. An RPO of 24 hours means daily backups are sufficient.
RPO drives backup frequency. RTO drives recovery automation. Together they determine the DR architecture and its cost. We have spoken with engineering teams that had documented RTO and RPO targets but had never modelled whether their existing backup schedule and recovery process could actually meet those targets. The gap is almost always in the recovery time, not the backup frequency.
Most Indian SMB and startup businesses have realistic RTOs of 4 to 24 hours and RPOs of 1 to 24 hours. This is the Backup and Restore tier of DR: achievable with automated backups to object storage and documented recovery runbooks, without the cost of any standby infrastructure.
Object Storage as the DR Foundation
Object storage is the ideal backup target for DR because it combines three properties that other backup targets do not offer together.
The first is durability. IBEE stores data with 11-nine durability (99.999999999%), on Tier 4 certified infrastructure. Data written to IBEE is not lost to hardware failure. The same data on an attached disk or a single-server NFS mount is one hardware failure away from loss.
The second is accessibility. Backups stored in object storage are accessible from any server, in any data centre, using standard HTTP, without mounting a volume, without VPN, and without special drivers. Recovery starts by provisioning a new server and pointing it at the backup bucket.
The third is cost. At Rs.1.50/GB/month ($0.016/GB/month), long-retention backup storage on IBEE is economically feasible. Keeping 12 months of full backups for a 500 GB database costs approximately Rs.9,000/month (~$95/month), a fraction of the cost of the business continuity event it exists to prevent.
The diagram below shows the three-layer backup architecture and the recovery path from each layer.
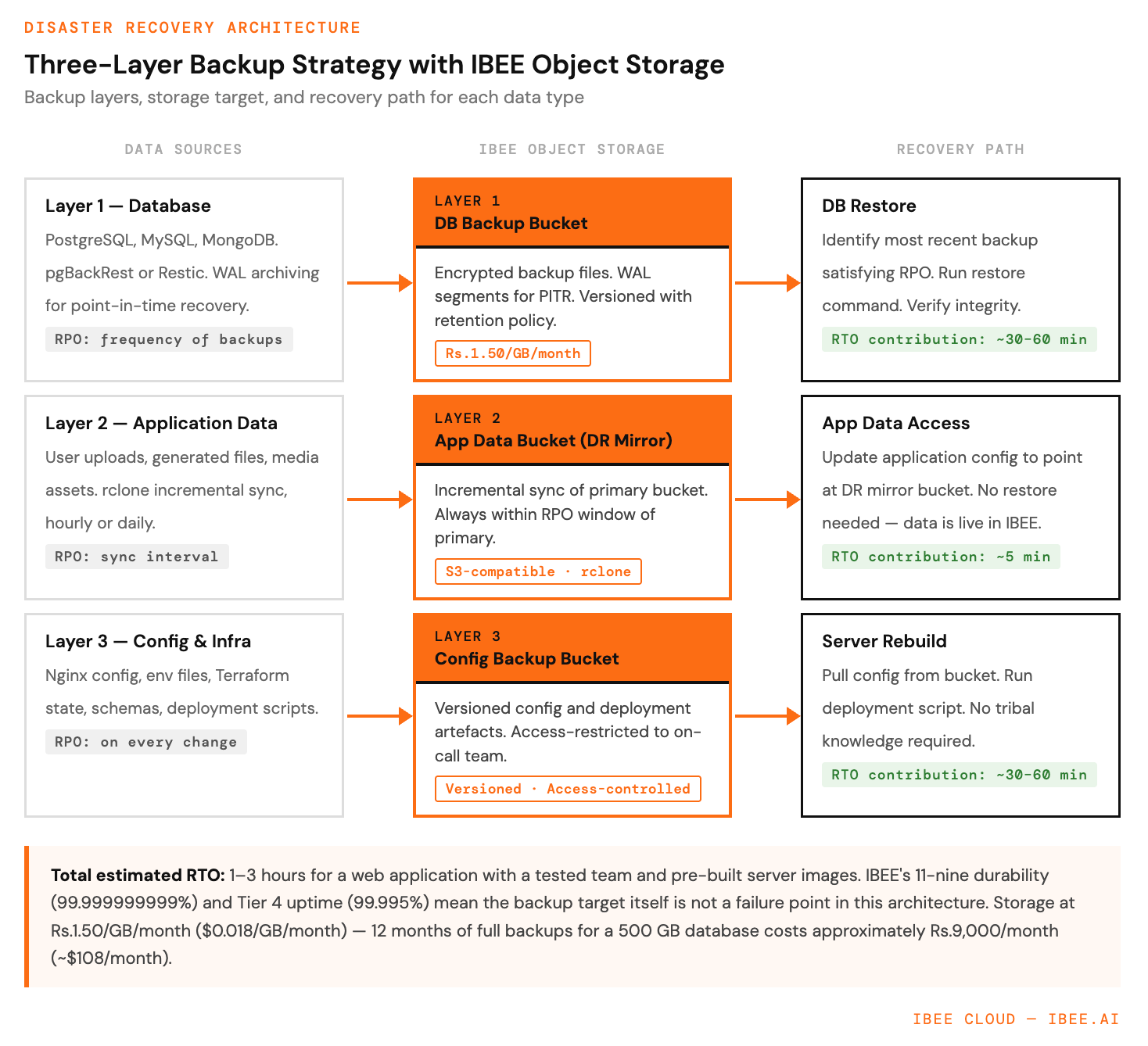
Three backup layers, one recovery path.
The Three-Layer Backup Architecture
Layer 1: Database Backups
Application databases, whether PostgreSQL, MySQL, or MongoDB, generate the most critical and irreplaceable data in most businesses. Database backups to object storage are covered in detail in the IBEE database backup guide, using pgBackRest for PostgreSQL and Restic for general workloads.
For DR purposes, the critical configuration is WAL archiving for PostgreSQL, which enables point-in-time recovery to any moment rather than just backup snapshots, and a backup retention period that matches the RPO. For an RPO of four hours, backups must run every four hours or WAL archiving must be continuous.
Layer 2: Application Data Backups
User-uploaded files, generated documents, media assets, and any other application data that lives in object storage or on server filesystems. If this data already lives in IBEE, the DR strategy is cross-bucket replication: syncing primary bucket contents to a secondary bucket using rclone on a scheduled basis. The sync is incremental, meaning only changed and new files are transferred on subsequent runs, keeping the secondary bucket current without full re-transfer. For an RPO of one hour, run the sync hourly. Full rclone configuration examples for IBEE are available at ibee.ai/docs.
Layer 3: Configuration and Infrastructure Backups
Nginx configuration, application environment files, Terraform state, database schemas, and deployment scripts: the configuration layer that tells a new server how to run the application. Store these in a dedicated IBEE bucket, versioned, with access limited to the on-call team.
A complete configuration backup means recovery from a total infrastructure loss requires only provisioning new servers, restoring the database from backup, pulling configuration from IBEE, and running the deployment script. No tribal knowledge required.
Cross-Provider DR Replication
For businesses where a provider-level failure is a DR scenario, unlikely at Tier 4 reliability but relevant for regulated businesses that require geographic and provider diversity, IBEE's S3 compatibility enables cross-provider replication using rclone. Configure rclone with credentials for both IBEE and a secondary provider and schedule a sync job to run daily or hourly. The secondary bucket holds a point-in-time copy of the primary, updated on every sync run. In a DR scenario, update the application configuration to point at the secondary bucket and recovery proceeds from there. Full cross-provider replication configuration is available at ibee.ai/docs.
The DR Runbook
A DR plan without a tested runbook is not a DR plan. It is a hope. The runbook is a step-by-step document that any on-call engineer can follow to execute recovery without specialised knowledge of the system internals.
Step 1: Assess the Failure
Identify which component has failed: database server, application server, network, or storage provider. Determine whether this is a recoverable incident where restarting the failed component is sufficient, or a DR scenario where the component cannot be recovered quickly enough to meet the RTO.
Step 2: Provision Replacement Infrastructure
Spin up a new server instance. Apply the saved server configuration from the IBEE configuration backup bucket. Install required packages using the recorded package list.
Step 3: Restore the Database
Identify the most recent backup in IBEE that satisfies the RPO. Run the restore command using pgBackRest, Restic, or the equivalent tool for the database engine. Verify database integrity after restore completes.
Step 4: Restore Object Storage Access
Update the application configuration with storage credentials. Verify read and write access to the primary or DR storage bucket.
Step 5: Deploy the Application
Run the documented deployment script. Verify the application starts correctly and passes health checks.
Step 6: Update DNS
Point the application domain to the new server IP. Verify end-to-end user access from an external network.
Step 7: Validate
Run through the critical user flows manually. Check error logs for unexpected failures. Confirm monitoring and alerting are active on the new infrastructure.
Total estimated time for this runbook with a tested team and pre-built server images is one to three hours, a comfortable RTO for most Indian businesses outside of financial services and critical infrastructure.
DR Testing
A DR plan that has never been tested has unknown reliability. Test the complete runbook quarterly, not just a backup integrity check but a complete recovery from a cold start. The test procedure is to provision a fresh server, follow the runbook exactly from Step 1, and measure the time to full recovery. Any step that requires undocumented tools, tribal knowledge, or manual intervention not captured in the runbook identifies a gap to fix before the next test.
IBEE's Tier 4 uptime of 99.995% means DR testing rarely coincides with an actual incident. Test in a staging environment to avoid any production impact.