Intelligent Network Design for Cloud-Scale Infrastructure
Building a Resilient, Self-Healing Edge Without Breaking the Data Plane.
I've seen teams spend months optimising compute and storage, then watch their platform go down because of a routing decision nobody thought through. Networking gets the blame when things go wrong. Here is how to make sure it doesn't.
"Up" Does Not Mean "Healthy"
Your monitoring says everything is fine. Meanwhile a transit link is degraded, an overlay tunnel has silently failed, and the router handling all of it is still responding to pings, cheerfully pretending nothing is wrong.
Traffic is blackholing. Users are timing out. Your dashboard is green.
Reachability and forwarding capability are not the same thing. A device can be perfectly reachable and completely unable to carry your traffic. Everything else in this article builds on that one idea.
Keep Your Control Plane Out of the Data Plane's Way
Hard rule: control plane changes must never be able to take down the data plane.
Your routing nodes should not run application logic. Your monitoring paths should not depend on production traffic paths. Your recovery automation should not introduce new dependencies when it fires.
When it all shares the same fate, a bug in your automation does not just break automation, it breaks traffic.
Build Gateways That Fix Themselves
Most teams build networks that need a human or a centralised orchestrator to notice a failure and respond. That works until the orchestrator becomes a single point of failure and the human gets paged at 2am.
Each gateway should handle its own failures without asking for permission. On failure: stop advertising itself, withdraw routing signals, shut off ingress. On recovery: bring itself back. No central controller involved.
Traffic flows away from broken nodes the moment something breaks. Recovery is faster. Blast radius is smaller.
Stop Checking If the Node Is Alive
A ping tells you a device is reachable. That is all.
What you actually need to know is: can this device safely carry traffic right now? A real health check should verify kernel routing readiness, next-hop reachability, external connectivity, internal fabric reachability, and routing protocol session state.
Build your checks around those five things and you catch the failures that actually hurt you.
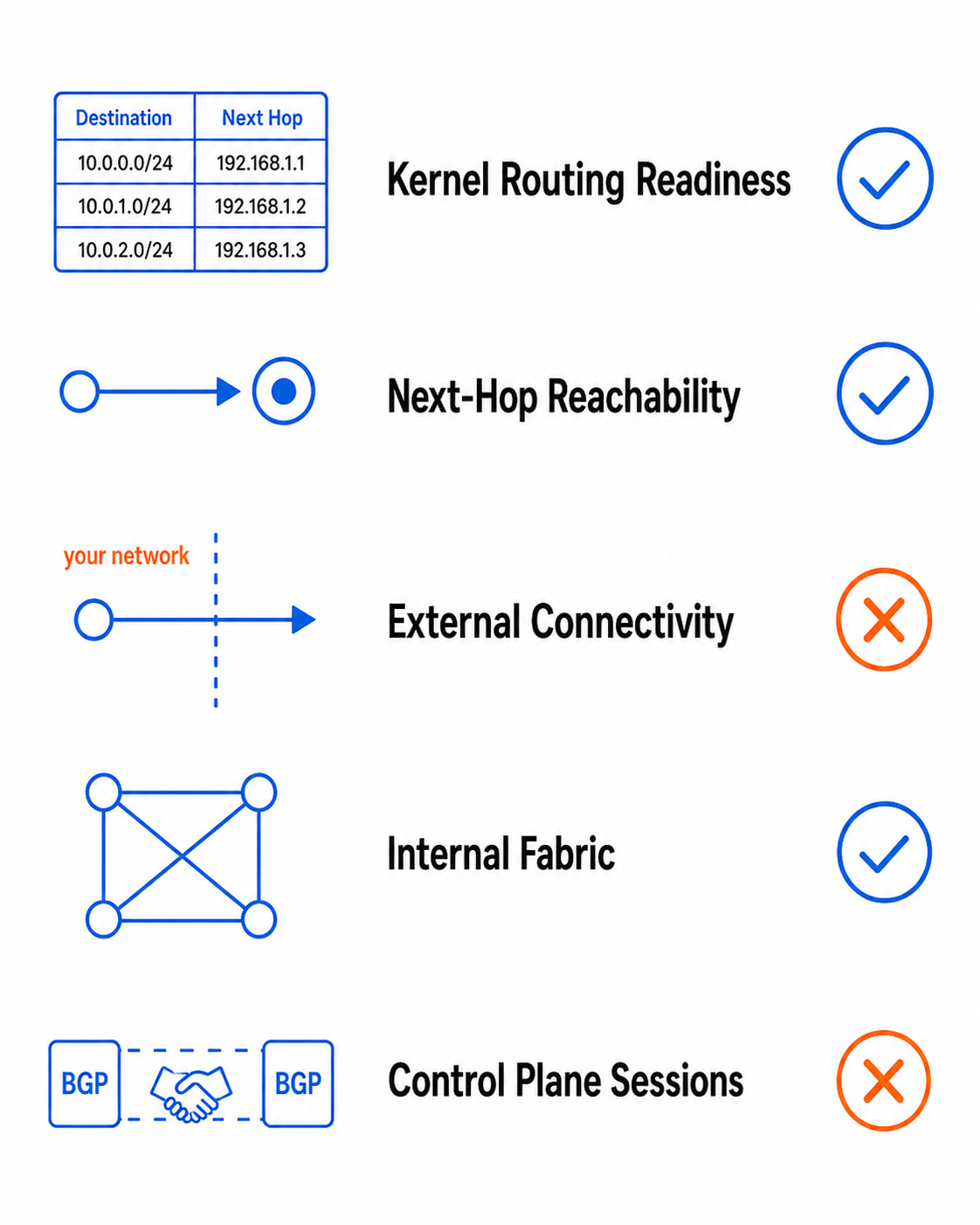
Five-layer network health check with pass or fail status indicators.
False Failovers Are Not Free
Routing session output formats differ between vendors, software versions, sometimes firmware builds. Your automation reads unexpected output, decides a healthy session is down, and triggers a failover that did not need to happen.
False failovers move traffic onto paths that weren't supposed to carry it, add load to healthy systems, and generate so much noise that operators start ignoring alerts — exactly when a real failure gets missed.
Test against actual device output. Pin to specific formats. Your automation should reflect how devices actually behave, not how you assumed they would.
Asymmetric Routing Is Fine. Broken Return Paths Are Not.
Traffic in via one provider, out via another — standard in DDoS scrubbing, anycast, and multi-transit environments. Not a problem on its own.
The problem is assuming symmetric routing and not validating return paths. If traffic comes in from a source your return path cannot reach, the session silently fails. The client times out. You see a healthy network.
Probe from outside your own network. Internal checks tell you what you control. External probes tell you what your users experience.
Logs Will Fill Your Disks If You Let Them
At scale, network events generate a lot of data. If it writes to your system partition, eventually something fills up — and when a partition fills up, unrelated things start failing in interesting ways.
Write logs to dedicated volumes. Set retention policies — twelve months rolling with compression covers most compliance requirements. Separate runtime, archival, and system journals so they don't compete.
Fixing a Small Problem Carelessly Creates a Bigger One
You add a default route to fix a reachability issue. It works. Three months later that default route is attracting traffic it was never meant to carry.
You route monitoring through the same path as production. Now a monitoring bug can disrupt the traffic it is watching.
Every one of these is a fix that worked temporarily and created a dependency that costs you later. A change that touches one system is controlled. A change that touches multiple systems is a risk multiplier — treat it as one.
The Goal Is Not Perfect Networks. It Is Networks That Fail Well.
Things will fail. The question is not whether your network will fail — it is whether the failure reaches your users.
The mindset shift that matters: from "detect and fix failures" to "prevent failures from reaching users." Detect-and-fix happens after the impact. Prevent-from-reaching happens before it.
Four things applied consistently get you there: isolate responsibilities, check real health not superficial signals, automate locally not from a central controller, and never sacrifice the data plane for convenience.
Get those right and you end up with infrastructure you can trust when it matters most.