
Why Computer Vision Has the Hardest Storage Problem in AI
An NLP model trains on text. Text is compact: a gigabyte of text contains hundreds of millions of words. A computer vision model trains on images. Images are large: a gigabyte of 512x512 pixel images at standard JPEG quality contains roughly 2,000 to 5,000 images.
A production document AI system that has processed ten million Aadhaar cards, PAN cards, and bank statements holds ten million images. At an average of 200 KB each, that is 2 TB of raw document images before annotations, processed versions, augmented training copies, or inference results. At one year of continuous collection, it is significantly more.
The storage infrastructure for a computer vision company is not a secondary concern. It is a foundational system that determines training efficiency, annotation pipeline capacity, and inference result accessibility. Getting it right early matters more than almost any other architectural decision you will make in year one.
Most CV teams we speak to discover this problem at the wrong moment: when a training run fails because the dataset directory was being written to mid-run, or when a compliance audit asks them to trace which annotator labelled which image from eight months ago and the answer is somewhere in a flat S3 bucket with no structure. The five-bucket pattern below prevents both problems.
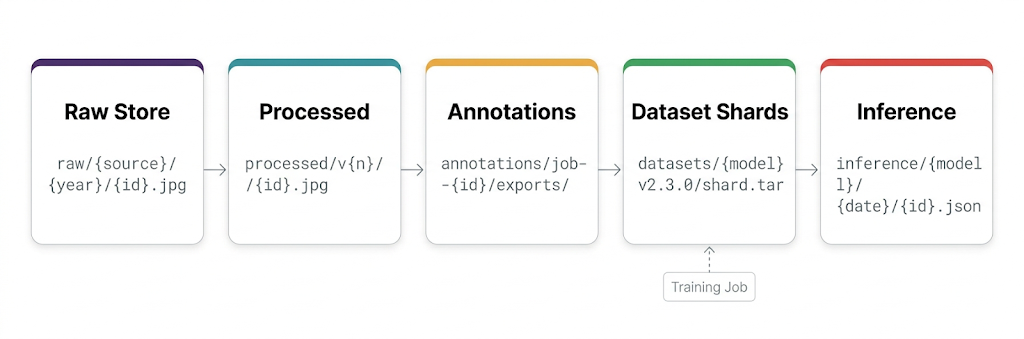
Images enter at the raw collection store and flow forward. Nothing is deleted. Every stage is versioned. Training jobs read only from sharded dataset buckets, never from raw or annotation stores directly.
The Five Storage Buckets Every CV Company Needs
Raw Image Collection Store
Raw images as captured from the source: camera uploads, scanner outputs, API data feeds, web scrapes, partner data dumps. Stored with a stable, deterministic key that identifies the image source, collection timestamp, and any available metadata.
raw/{source}/{year}/{month}/{image-id}.jpg
This bucket is write-once, never-delete. Every raw image that enters the system is preserved here regardless of whether it was used for training, rejected during quality filtering, or later found to contain PII that required annotation redaction. The raw store is the legal record of what data the company collected.
For CV companies working with biometric data (face images, fingerprints), medical images, or government identity documents, the raw store carries data residency obligations under the DPDP Act. These images must remain on India-sovereign infrastructure.
Quality-Filtered and Pre-Processed Images
Not every raw image is suitable for training. Blurry images, incorrectly rotated documents, images with corrupted data, images that fail quality thresholds: these are filtered out before annotation. Remaining images are pre-processed — standardised to a consistent resolution and format, colour normalised if applicable.
processed/v{n}/{image-id}.jpg
The version number increments when the pre-processing pipeline changes. When you update the deblurring algorithm or change the normalisation parameters, you re-process raw images and write to a new version prefix, preserving the old processed version for comparison. This sounds like extra work. It prevents the much more expensive work of trying to figure out why model performance changed after a pipeline update.
Annotation Assets and Exports
Images sent to annotators and the annotation outputs they produce. Organised by annotation job ID:
annotations/job-{id}/assets/ ← images sent to annotators
annotations/job-{id}/exports/ ← label files returned
Annotation exports are retained indefinitely. When disagreements arise about label quality, when annotation tools change, or when a compliance audit requires tracing which annotator labelled which image, the annotation export is the primary record. The teams that delete these exports to save storage costs are the ones who later spend three weeks reconstructing label provenance under deadline pressure.
Training-Ready Dataset Shards
WebDataset-format tar shards built from processed images and their final labels. Each shard contains matched image and annotation files for 500 to 1,000 training examples. Versioned by dataset version:
datasets/{model-type}/v2.3.0/train/shard-{n:06d}.tar
This is the bucket your training jobs read from. The format (sharded tar archives) and versioning scheme ensure that a training run always reads a deterministic, complete dataset, not a partial view of a directory that is being updated while training is running. If you have ever had a training run produce a model you cannot reproduce because the dataset changed between runs, this structure is the fix.
Inference Results and Audit Logs
Production inference results stored for audit, quality monitoring, and model performance analysis. For document AI, this means storing the extracted fields, confidence scores, and error flags for every document processed.
inference/{model-version}/{date}/{request-id}.json
This store enables model quality analysis over time (are confidence scores declining as data distribution drifts?), A/B testing between model versions, and compliance audits that require tracing which model version processed a specific document.
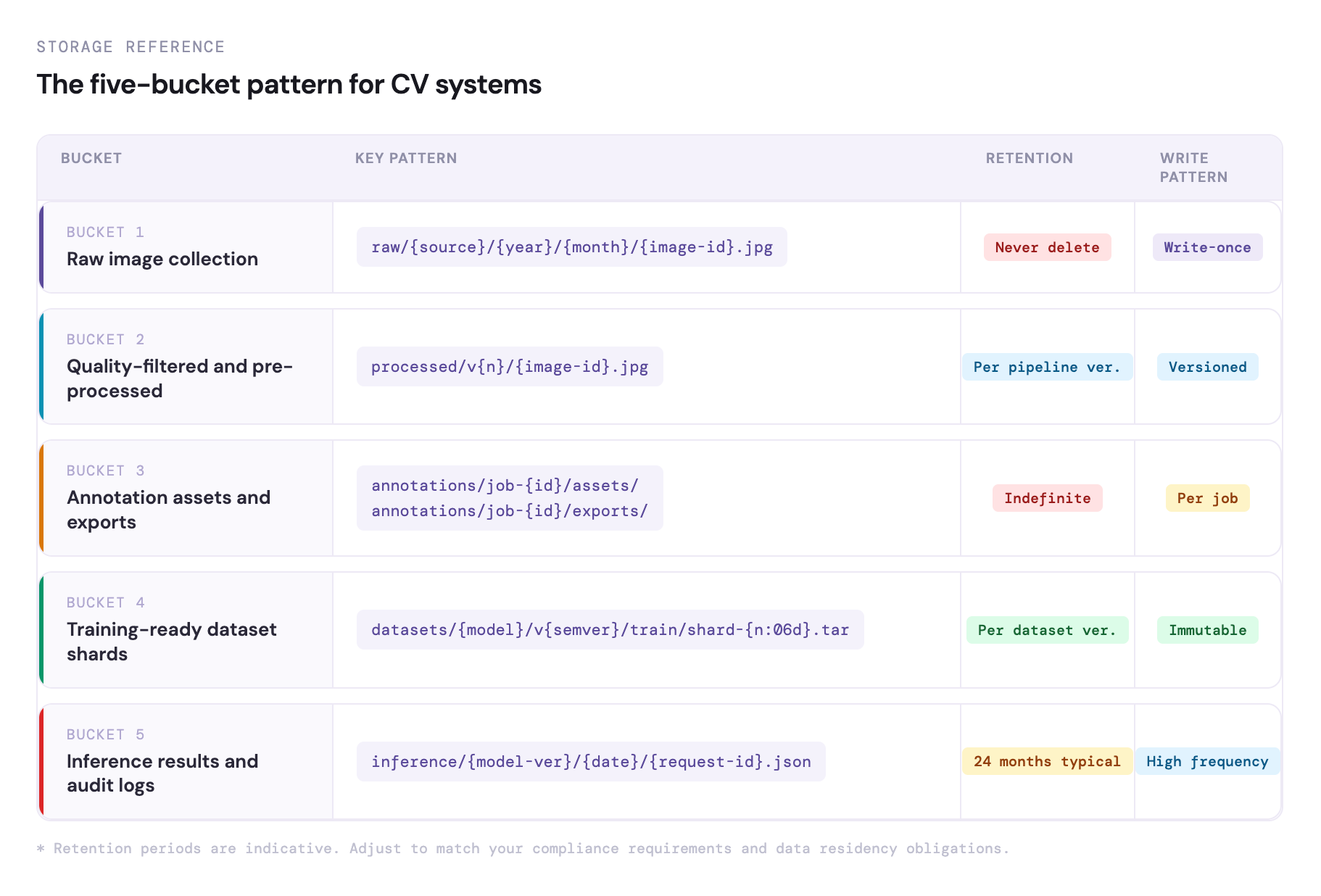
The five-bucket reference.
Annotation Pipeline Architecture
The annotation pipeline connects raw image data to the final training dataset. In a real production CV system, it handles thousands of images daily, so it needs to be reliable enough that delays in annotation do not slow down training.
The process starts with image selection. A pipeline picks images from the raw storage that meet quality standards and have not been annotated before. In setups using active learning, it focuses on images where the model is uncertain, so each annotation adds more value.
Next is asset preparation. Selected images are pre-processed and uploaded to an annotation bucket. At the same time, a job record is created in the database with details like image IDs, schema version, assigned team, and expected completion time.
Once annotation is done, the export file is pulled from the tool and stored in an exports bucket. A validation step checks format, ensures labels are complete, and flags any inconsistencies. Final labels are then saved in the database.
Finally, the training data update step takes these validated annotations, packages them into dataset shards, and writes a new version to the training bucket. A new version is created only when the dataset is complete, not for partial updates.
Production Inference Storage Patterns
For a CV system processing documents at production scale, thousands per day, the inference result store must handle high write throughput, support time-range queries for monitoring, and retain results for compliance periods.
Write inference results as JSON objects to IBEE with the request ID as the key. The JSON contains the input document identifier (not the document itself — the raw document is in bucket 1), the model version used, the extracted fields and their confidence scores, any detected error conditions, and the processing timestamp.
A daily manifest file at inference/{model-version}/{date}/manifest.json lists all request IDs processed that day, enabling efficient batch retrieval for daily quality reports without scanning all objects in the date prefix.
Lifecycle policies expire inference results after the compliance retention period: typically 24 months for document AI in BFSI (banking, financial services, and insurance) applications, configurable per use case.
Data Residency for Indian CV Applications
Computer vision systems in India often deal with biometric data, medical images, and government ID documents, all of which come with strict data residency requirements.
Under the DPDP Act, biometric and health data are treated as sensitive. Companies handling this data are expected to apply strong technical and organisational controls. If this data is stored on infrastructure operated by a foreign entity, it creates legal uncertainty that usually comes up during audits or enterprise procurement, often at the worst possible time.
With IBEE, all parts of the pipeline, raw images, annotation assets, and inference results, stay within India on locally governed infrastructure. For CV companies working with BFSI, healthcare, or government clients, this is not just a preference. It is often a requirement to even move forward with enterprise deals.
