For technical co-founders, founding engineers, and early CTOs at AI startups from pre-seed through Series A.
Why AI Startup Infrastructure Decisions Are Harder to Reverse
Most of the AI founders we have spoken to made at least one of these decisions wrong in first year. Not because they were careless but because nobody told them the problem of getting it wrong before they had already paid for it.
A typical software startup can still rework its infrastructure around Series A with about a month of engineering effort and some manageable disruption. But for an AI startup, it is not that easy or cheap, mainly because the infrastructure and the data are deeply connected.
The way you design your storage setup directly affects how your training data is organised. And the way your data is organised impacts how quickly you can experiment and improve your models. That speed of iteration then plays a big role in deciding your product quality and how fast you can bring it to market.
So unlike traditional startups, AI startups cannot easily change things later, because early infrastructure decisions end up shaping their entire development pace.
An AI startup that builds its data collection pipeline without versioning quickly runs into trouble when it tries to reproduce experiments from six months ago. If the training data is stored on a single attached disk, scaling training across multiple GPUs becomes difficult without reworking the entire setup. And if hyperscaler storage is chosen without considering data residency, closing the first enterprise deal in sectors like BFSI or healthcare can suddenly require a rushed migration under tight deadlines.
These are not just edge cases. They are patterns that experienced founders and investors keep noticing, both in India and globally. The infrastructure choices made in the first six months tend to stick with the company for the next two to three years, so taking the time to make informed decisions early on really matters.
We have seen this happen so often that it almost feels predictable. A well-funded AI startup, about 14 months in, suddenly realises that all its training data sits in a flat bucket of around 200,000 files, with no versioning and no clear lineage. Fixing this takes weeks, often around six, and the Series A timeline does not wait.
Data Storage: Why Structure Matters More Than GPU Choice
The most important infrastructure decision for an AI startup is usually not the GPU you pick or even the model architecture. It is how you structure your data storage.
In AI, training data is what really gives you an edge. The quality, quantity, and how well your data is organised decide how far your models can go. If your storage setup makes it easy to collect data, annotate it, and version datasets properly, it keeps paying off over time. But if everything just piles up in an unstructured bucket, it turns into a mess later when you actually need to trace what data was used to train your models.
The most common issue is not that teams lose data, it is that they lose context. A folder named something like training-data-final-v3-USE-THIS might sound important, but it does not tell you how that data was created, what filters were applied, or if it even matches the dataset that trained your last working model.
A better approach from the start is to keep things clearly separated. Have different buckets for raw collected data, processed and filtered data, annotation outputs, versioned training datasets, and model artifacts. Each of these should have a clear owner, defined access rules, and a naming system that actually captures useful metadata.
Raw data should be treated as immutable and never deleted. Processed data should be versioned based on the pipeline that generated it. Training datasets should follow proper versioning, and model artifacts should always be linked back to the dataset version and code used to create them.
This might sound like extra effort at an early stage, but it is not over-engineering. It is the basic setup needed for any company where the core product is a trained model.
From IBEE perspective, there is no real downside to doing this properly. Storage is priced at ₹1.5 per GB per month, and you are not penalised for using multiple buckets. Data uploads and internal traffic are free, and egress costs ₹2 per GB. So organising your data the right way from day one does not add complexity in cost, but it saves you a lot of trouble later.
GPU Procurement: Rent Before You Commit
The GPU market has changed a lot in the last couple of years. Today, you can rent GPU compute from multiple providers, both in India and globally, with options like A10, A100, and H100 available on an hourly basis. For an early-stage AI startup, this makes renting a much more practical choice than buying.
Buying GPUs at the seed stage means you are trying to guess your compute needs almost two years in advance. That is very hard in AI, because your future requirements depend on things like how much data you collect, what model architecture you end up choosing, and what benchmarks you aim for. At the time of purchase, none of this is really clear.
On the other hand, renting GPUs means you only pay for the time you actually use them. For example, fine-tuning a 7B parameter model on around 10,000 documents can take about 6 to 12 hours on a single A100. At roughly $2.40 to $4.80 per hour, that comes out to around $14 to $58 per run. If you compare that to buying a GPU, which can cost anywhere between $18,000 and $30,000 and still depreciates over a few years whether you use it or not, renting makes a lot more sense early on.
The numbers make this clear:
GPU rental vs ownership cost comparison for AI startups at seed and Series A stage.
There are some scenario where owned GPUs make sense earlier: if you are doing repeated, predictable fine-tuning runs on a fixed-size dataset at a cadence you can actually project or data security is your biggest concern.
For most of the startup the rule for the first two years: rent GPU compute for training, use CPU inference for early product, and evaluate owned GPU hardware only when you can confidently project training runs that would cost more in rental than in owned hardware amortisation.
Data Residency: Make the Right Choice Before You Have Data
Indian AI startups working with user data like health records, financial documents, language inputs, or biometric data have to make an important call around data residency. It is much easier to decide this early, before your data grows too large.
The key question is simple: where is your training data stored, and under which legal system? If you are using services like AWS S3, Google Cloud Storage, or Azure Blob Storage, your data is managed by US-based companies and comes under US laws. For many consumer apps this might not feel urgent, but for enterprise deals in sectors like BFSI, healthcare, or government, it is a serious concern.
One founder explained this clearly: after months of working on a deal with a large private bank, everything came down to a single compliance question about where their training data was stored. They could not give a clear answer, and the deal was lost.
This usually becomes a problem during your first serious enterprise sales conversation. If the answer is something like AWS US-East, it often raises concerns. Some startups end up pausing deals for months just to migrate their data. Making this decision early avoids that situation completely.
Starting with India-based storage means you do not have to worry about this later. IBEE, for example, operates Tier 4 infrastructure in India under Indian law, while still offering an S3-compatible API. So your existing pipelines and tools continue to work with minimal changes.
The cost of deciding early is basically zero. But delaying it until you already have hundreds of terabytes of data and active investors can turn it into a stressful migration at the worst possible time.
Model Serving Architecture: Separate from Training Early
AI startups often begin by using the same setup for both training and serving their models. The same GPU that trains the model is also used to handle inference requests. This works fine at the early stage when usage is low, but it starts causing reliability and cost issues once production traffic grows.
The reason is that training and inference have very different needs. Training is batch-based, can be paused, and is not sensitive to delays. If a run takes a bit longer, it is usually not a big deal. Inference, on the other hand, is real-time, latency-sensitive, and expected to be always available.
When both run on the same GPU, they start interfering with each other. Training jobs can get interrupted by incoming requests, and inference performance becomes inconsistent because both are competing for GPU memory.
A better approach is to separate them early. Object storage acts as the bridge, where training jobs store model artifacts and the serving system loads them when needed. This way, new model versions can be deployed without affecting the live serving setup.
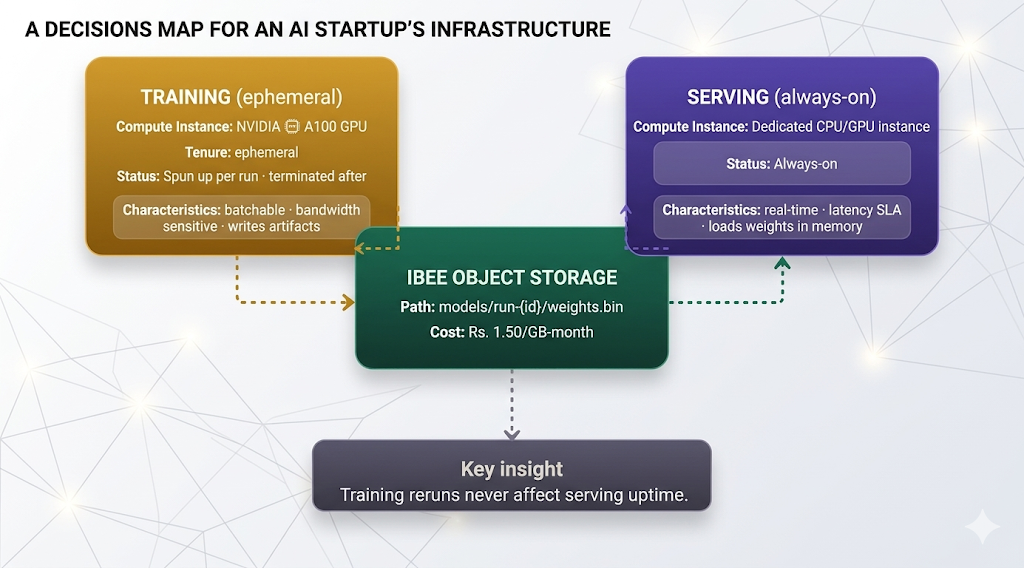
Training and serving are fully decoupled via object storage. A new training run never affects serving availability.
Many teams delay this separation because they want to move quickly, which makes sense early on. But it often backfires. A heavy training job running at odd hours can easily consume all GPU resources and bring down the inference API that users depend on.
A cleaner setup is to run training on temporary GPU instances that are created for each job and shut down after completion. Inference should run on a dedicated, always-on instance, either CPU or GPU, depending on traffic needs. Model weights are loaded from object storage when the service starts and kept in memory for fast access.
Experiment Tracking: Instrument Before You Need It
One of the most frustrating things in early AI startups is not being able to reproduce a great result from a few months ago. The model that performed best was trained by someone who has since left, on a dataset that got overwritten, using code that no longer exists in the same form.
It usually looks something like this: the best model came from an engineer who is gone, the dataset was saved in a folder with a vague name like data_new_cleaned_for_real, the commit history was cleaned up, and the hyperparameters are buried in an old Slack message. This is not rare, it is one of the most common regrets founders talk about at Series A.
The solution is experiment tracking. Tools like MLflow, Weights & Biases, or even a simple structured logging setup can capture the three key things needed to reproduce any run: the code version, the dataset version, and the hyperparameters. Without this, good results are hard to repeat and bad ones are hard to debug.
It is best to set this up from the very first training run. The effort is minimal, usually just logging metrics and artifacts, but the benefits build up with every experiment.
Store artifacts like checkpoints, final model weights, and evaluation reports in IBEE using a clear structure that includes the run ID. That way, if you ever need to roll back or revisit a model, everything is organised and easy to trace.
The Pattern of Well-Built AI Startups
The AI companies that successfully navigate seed to Series A share a consistent infrastructure pattern: their training data is structured and versioned from day one, their storage is on infrastructure they control, whether in India or closer to their users, their GPU spend is on rental compute with no committed capital, their training and serving architectures are separated, and their experiment tracking gives them full reproducibility on any run from the last 18 months.
None of these decisions require large upfront investments. All of them require deliberate choices made before the defaults take hold.

